
前言
友思特 Neuro-T 支持的深度学习模型类型

分类
将图像分类成不同的类别或OK/NG组别

实例分割
分析图像中检测到的物体形状并圈选

监督学习
检测图像中物体的类别、数量并定位
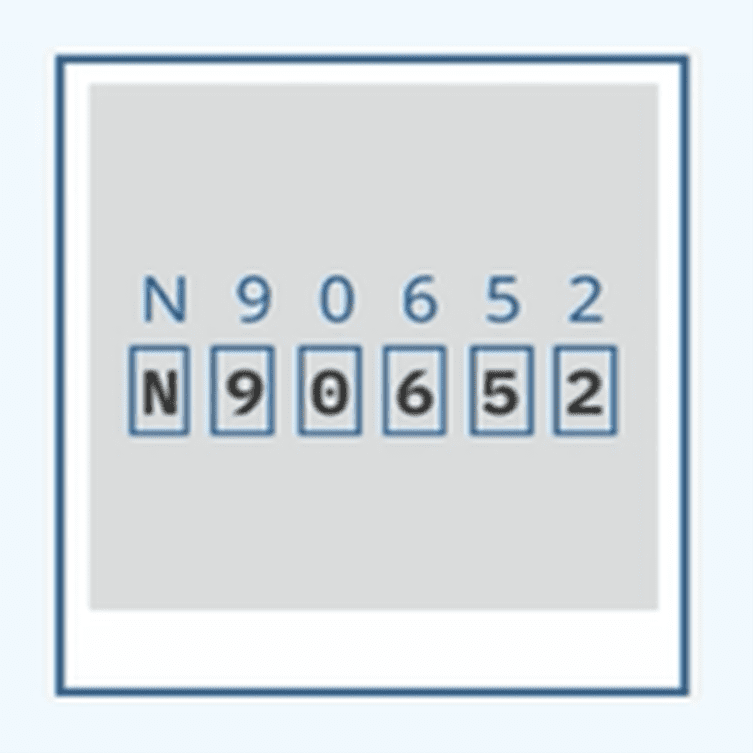
OCR字符识别
检测和识别图像中的字母、数字或符号
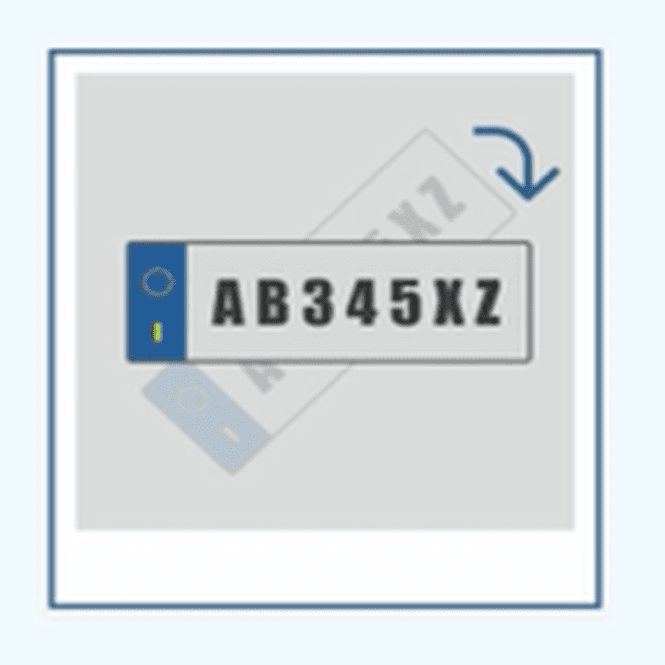
旋转
旋转图像至合适的方位
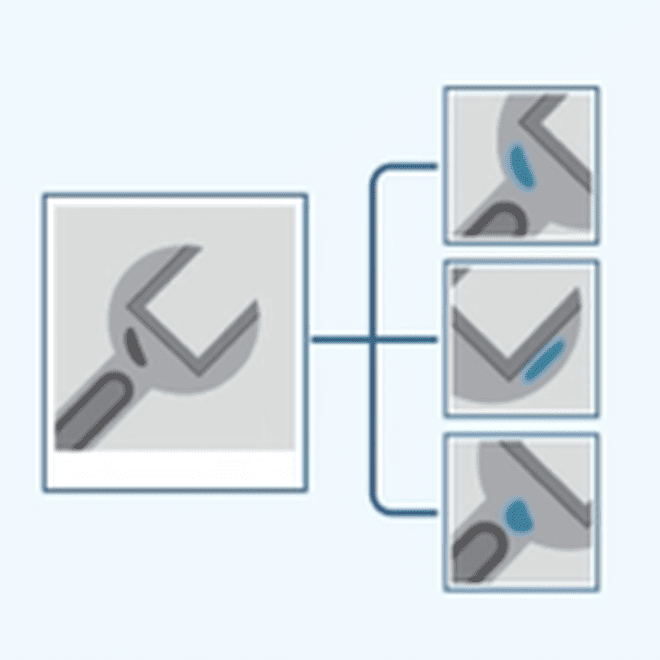
GAN对抗生成网络
学习图像中的缺陷区域并生成虚拟缺陷

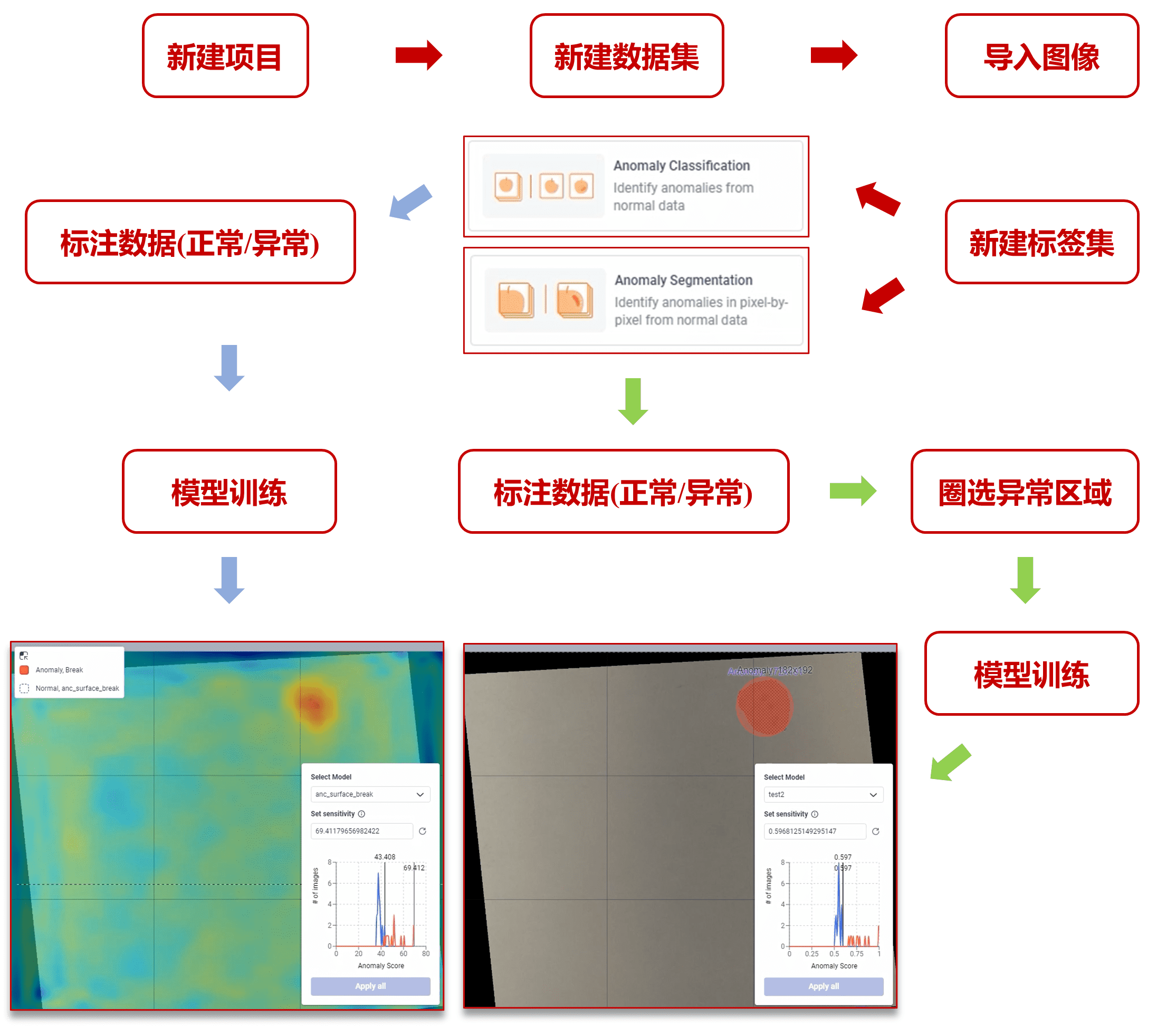
异常分类
在大量正常图像和少量缺陷图像上
训练以检测异常图像进行分类

异常分割
在大量正常图像和少量缺陷图像上训练以检测异常图像并定位缺陷位置
Neuro-T GAN 模型生成缺陷图像操作步骤
1.1.1 新建项目
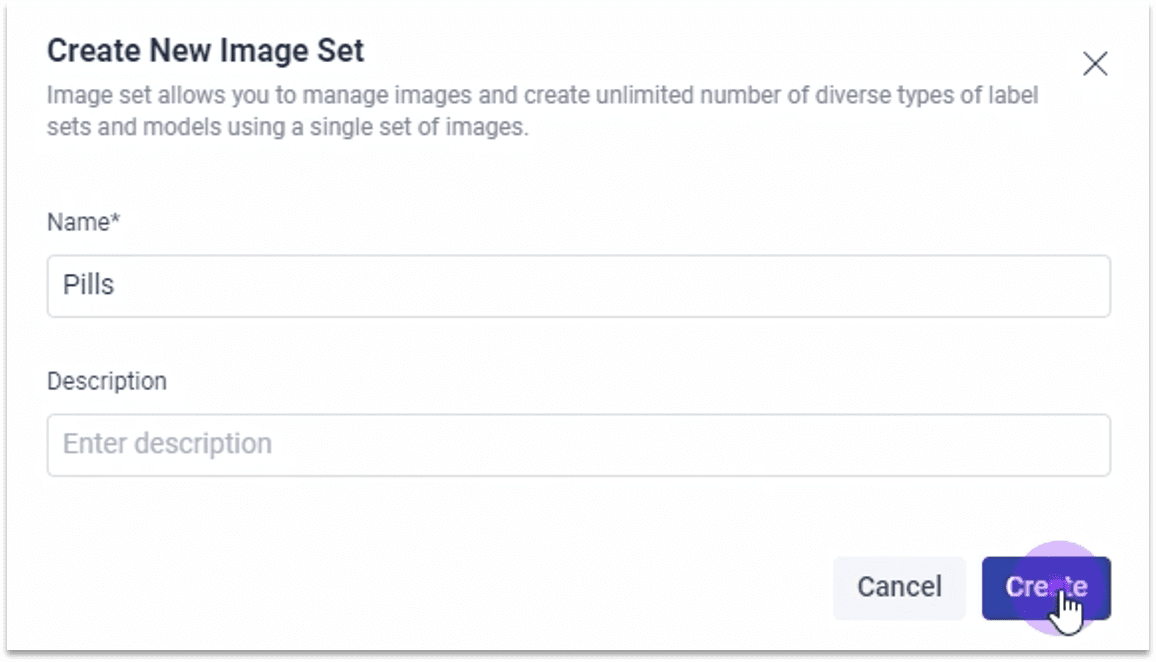
1.1.2 新建数据集
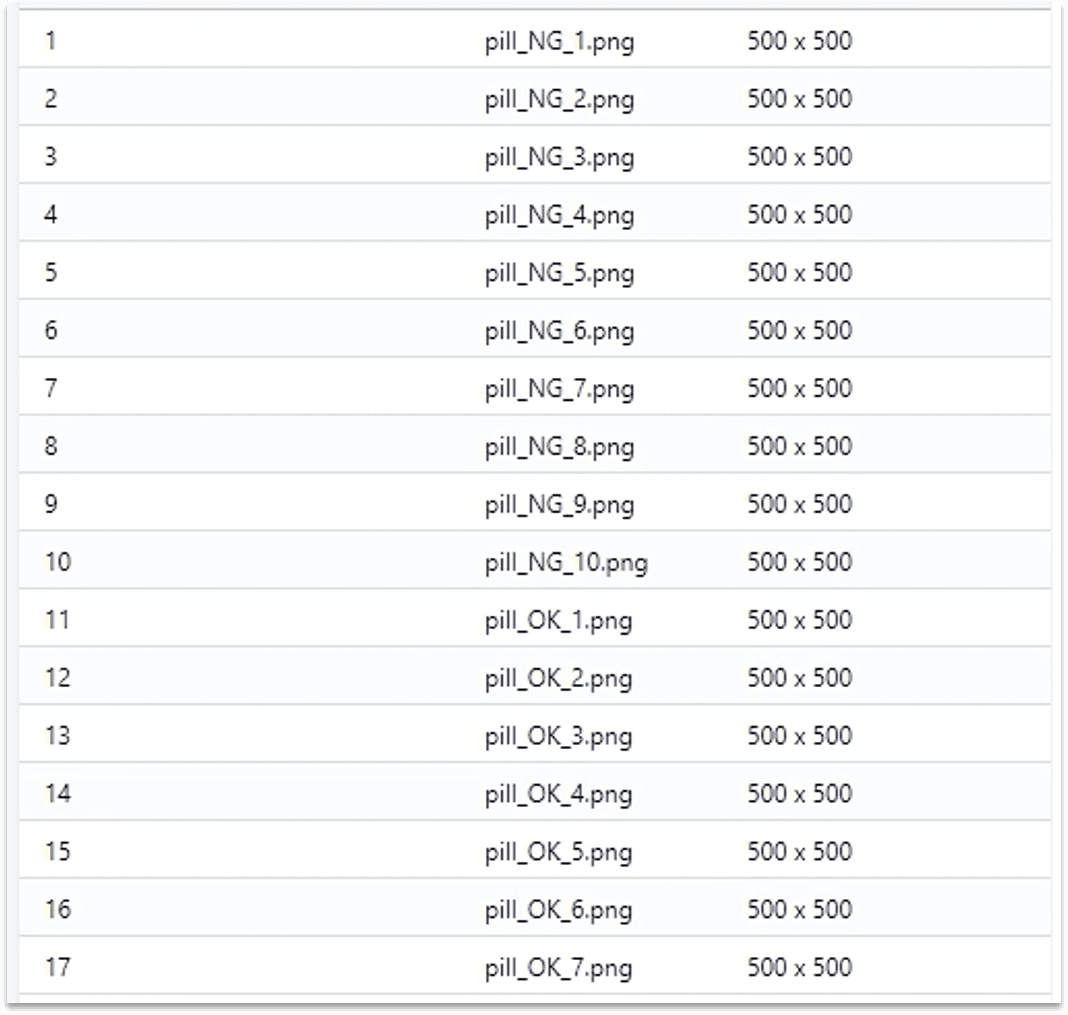
1.1.3 导入图像数据
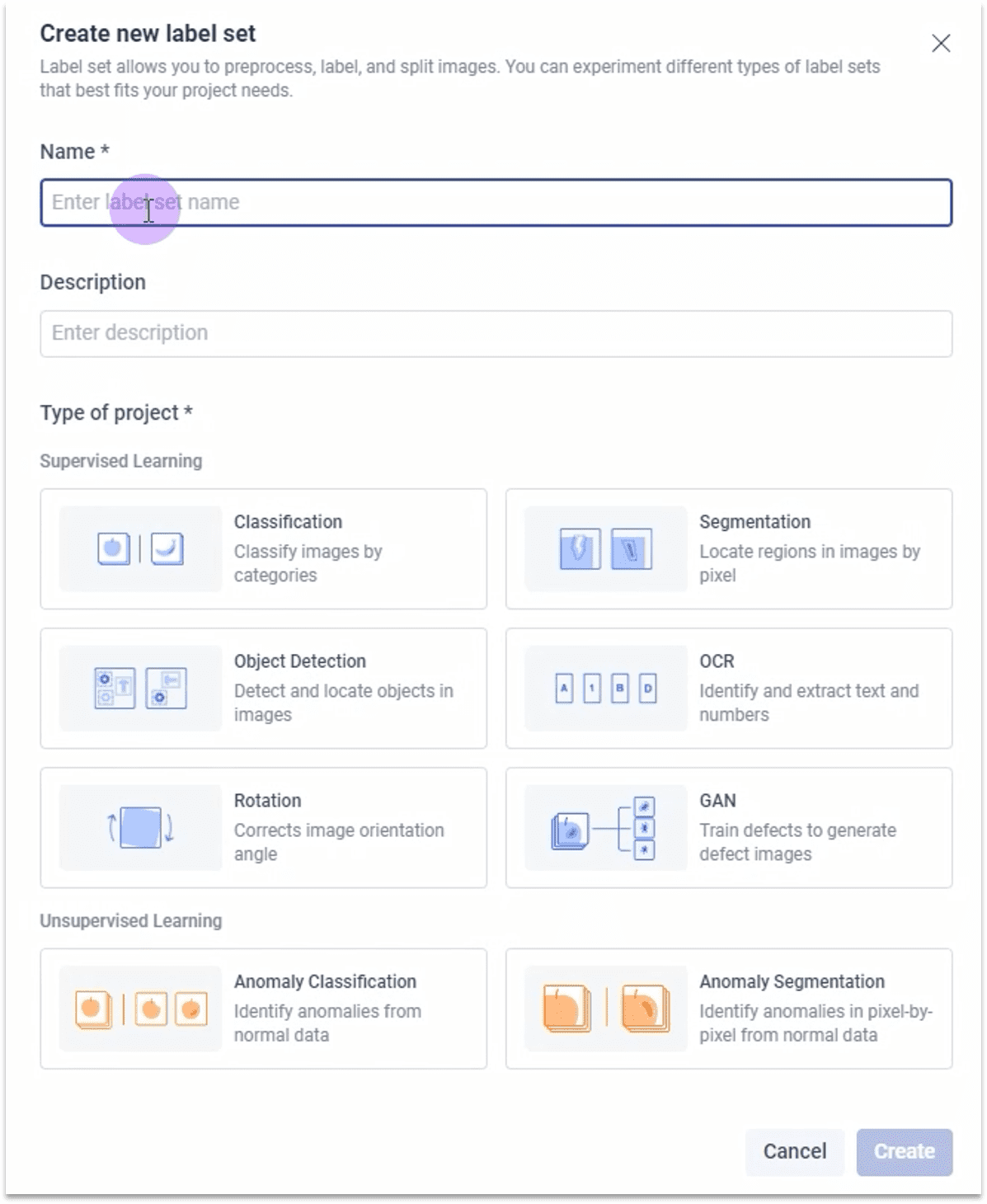
1.2.1 创建标签集
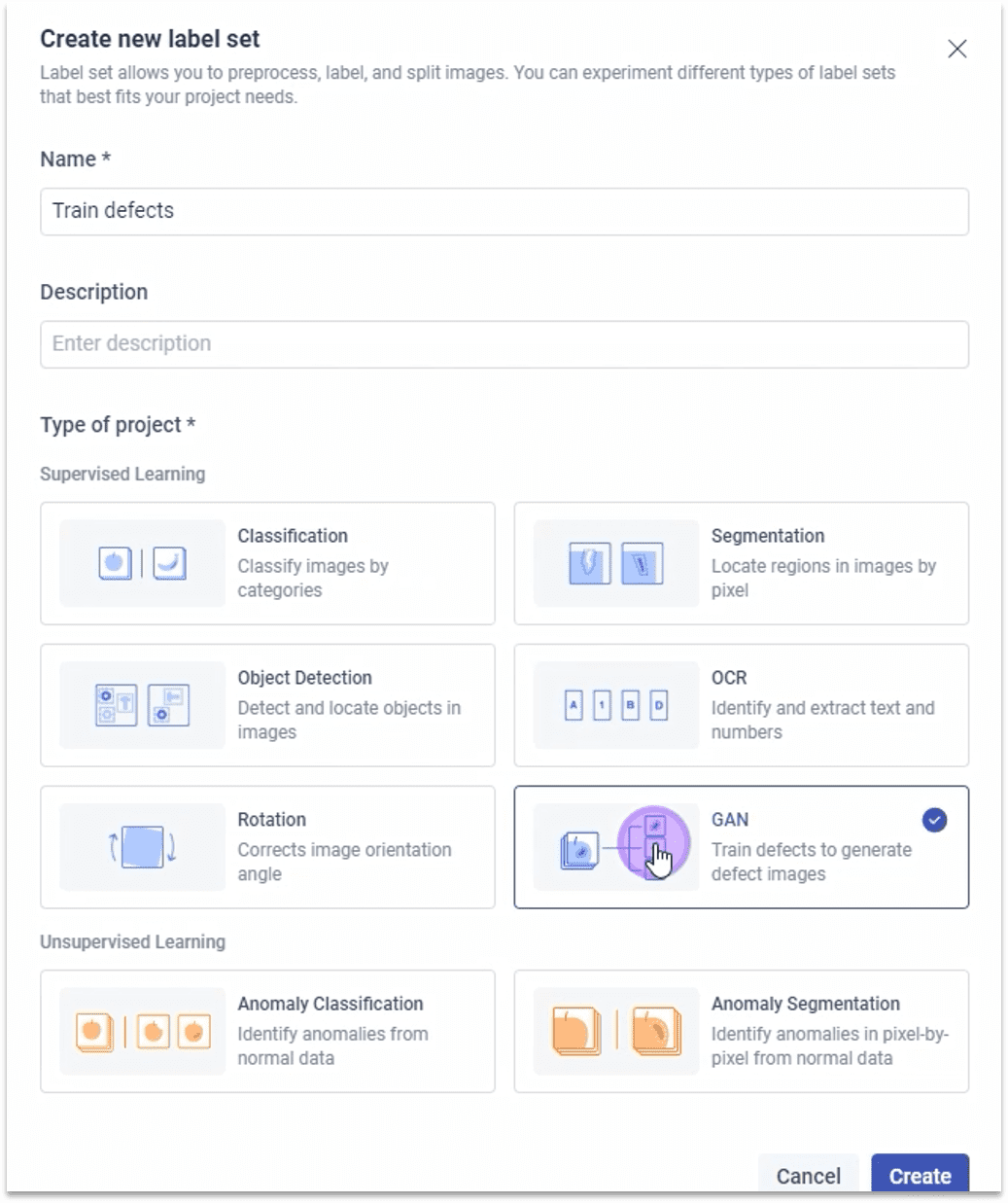
1.2.2 选择模型类型(GAN)
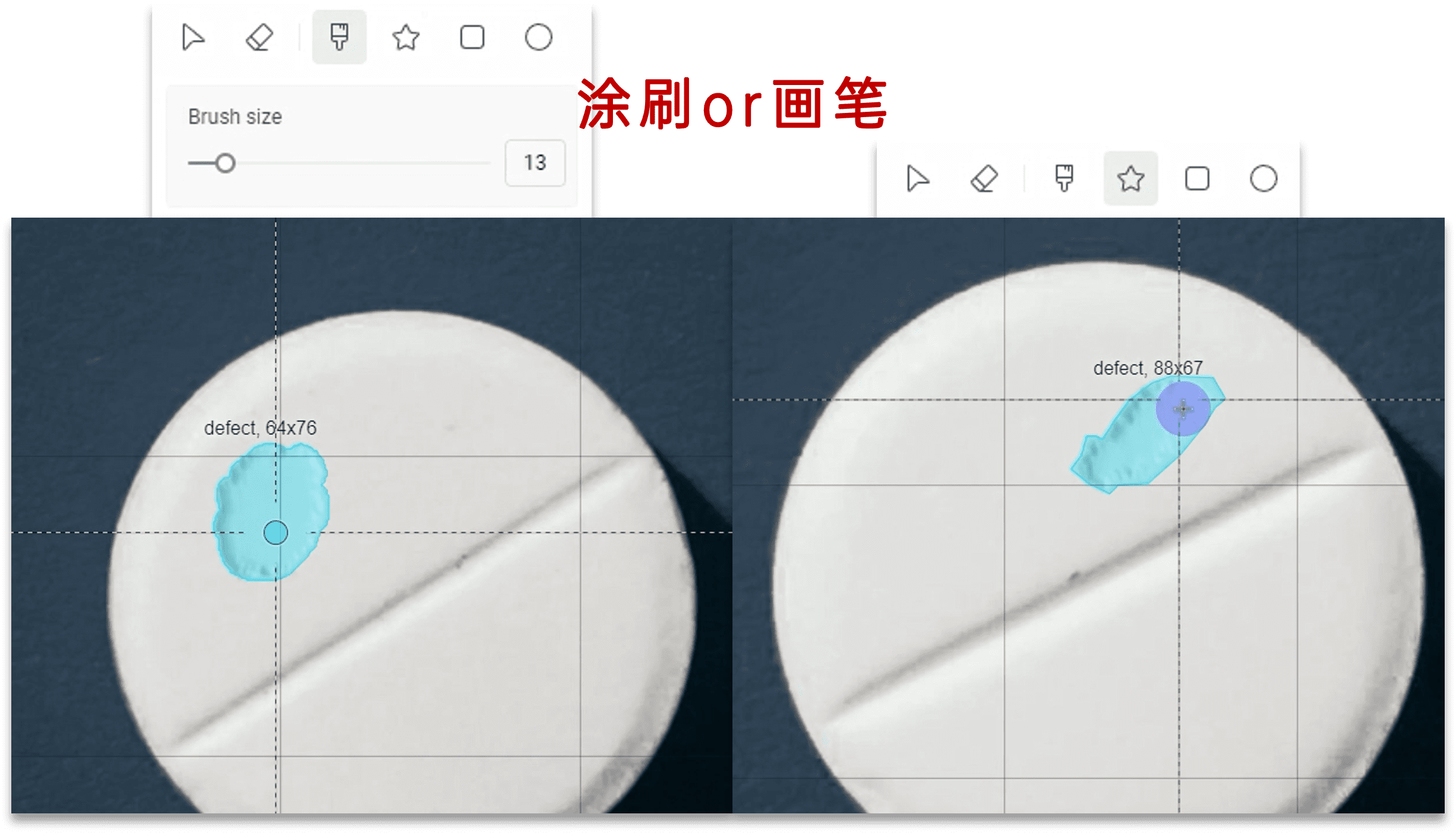
1.3.1 标注数据
可以使用涂刷的方式选中缺陷区域
也可以用画笔绘制任意多边形圈选缺陷区域
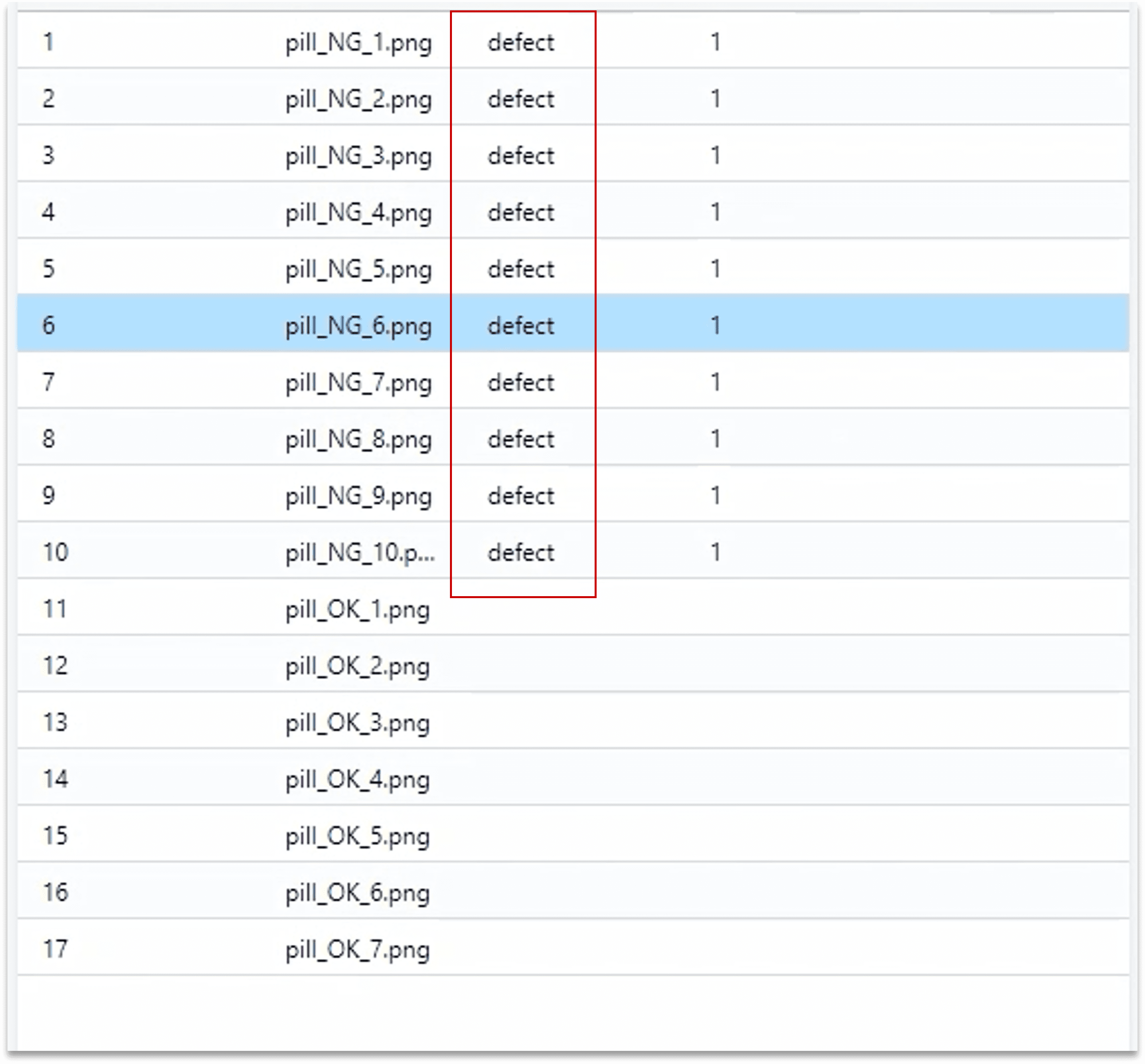
1.3.2 完成标注
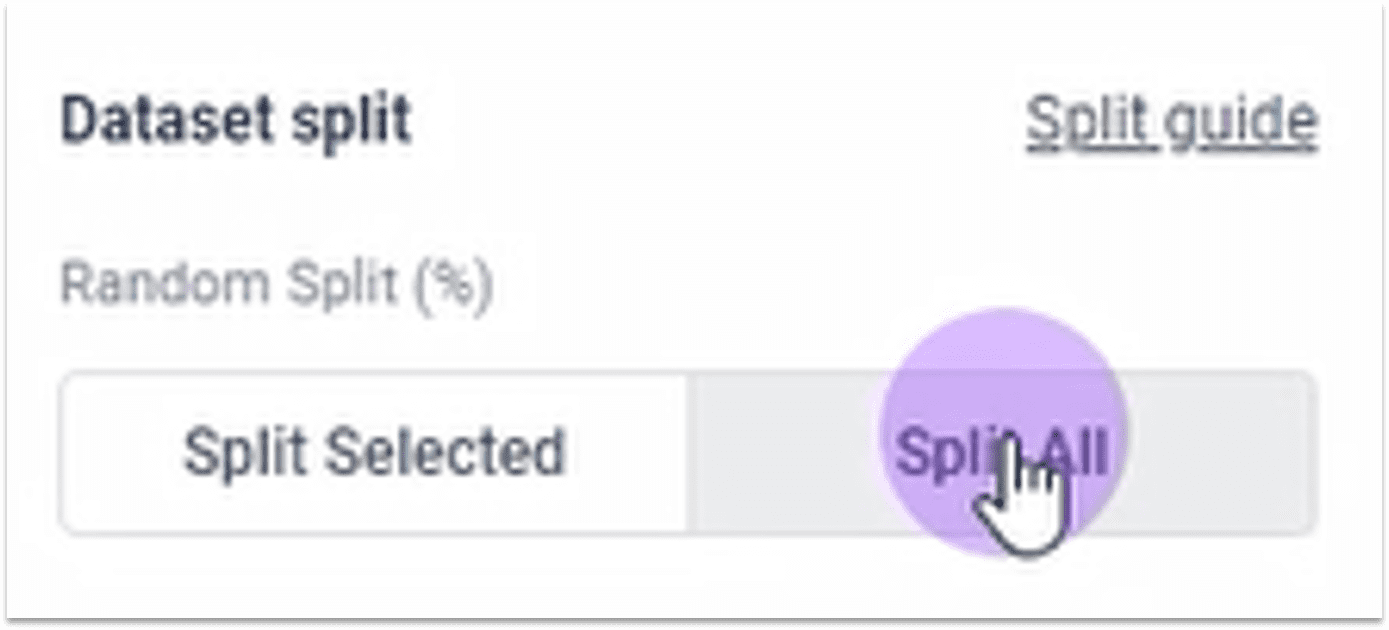
1.4.1 划分训练集/测试集
将缺陷图像设置为训练集
将正常图像设置为测试集
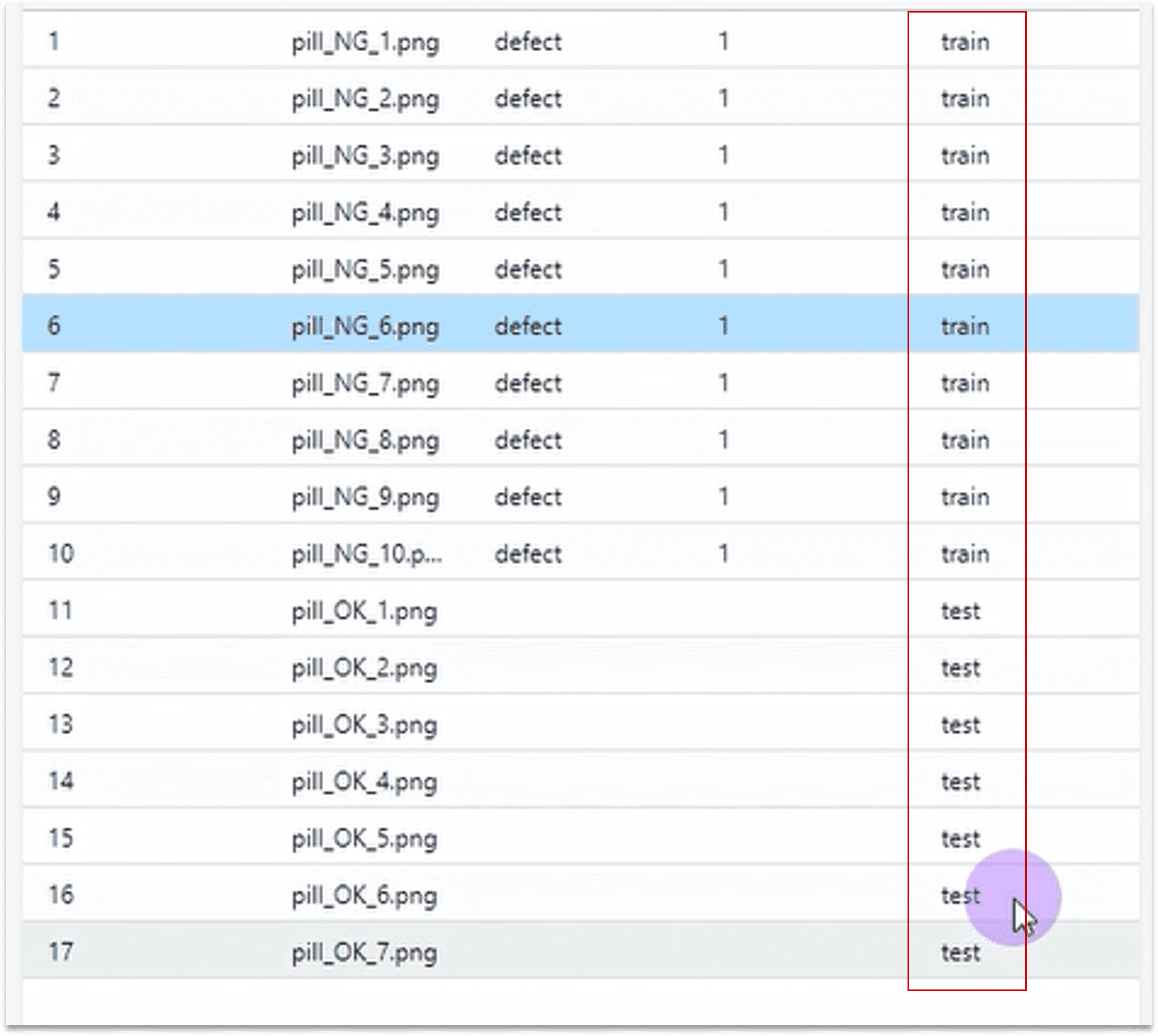
1.4.2 缺陷图像/正常图像
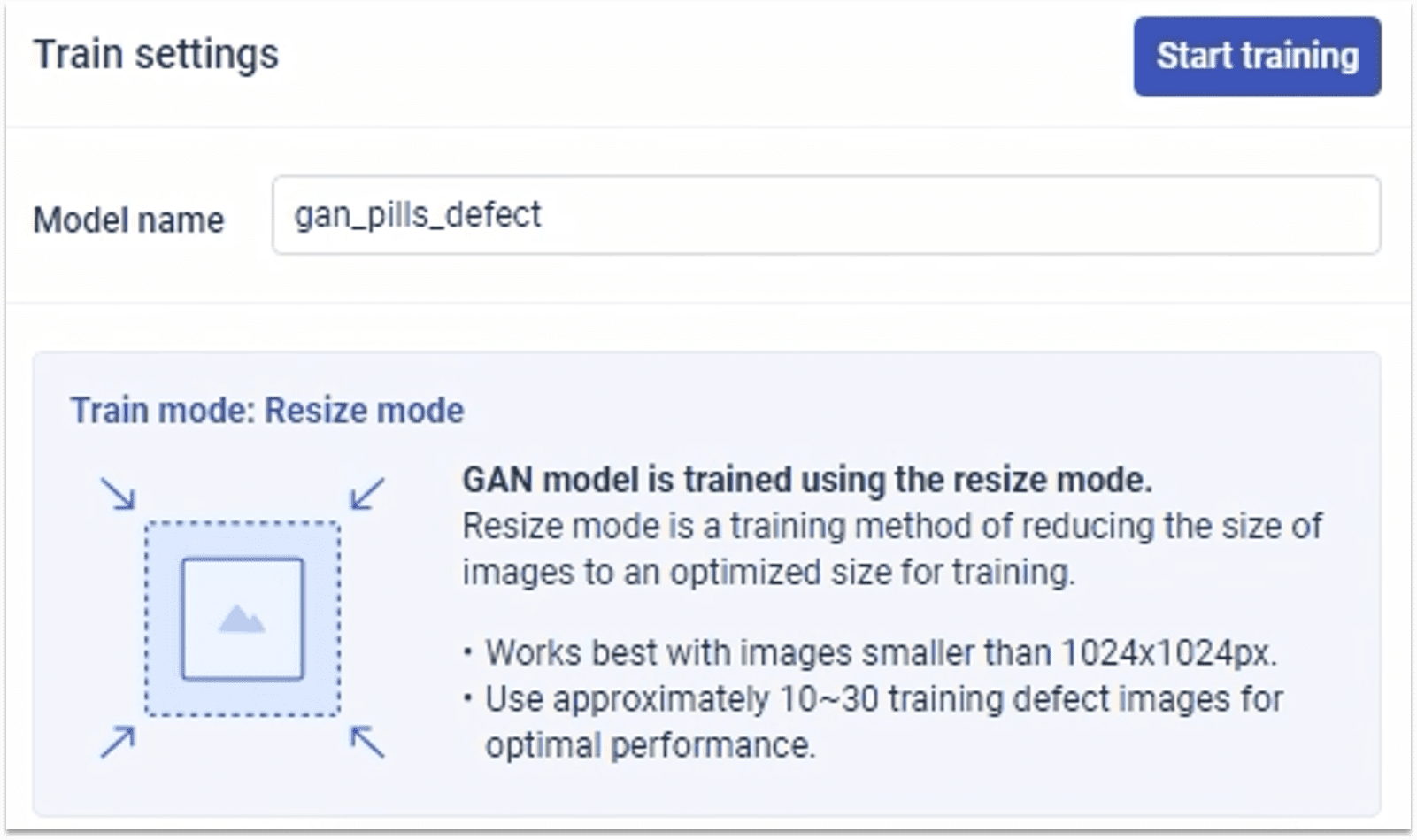
1.5.1 输入训练模型名称
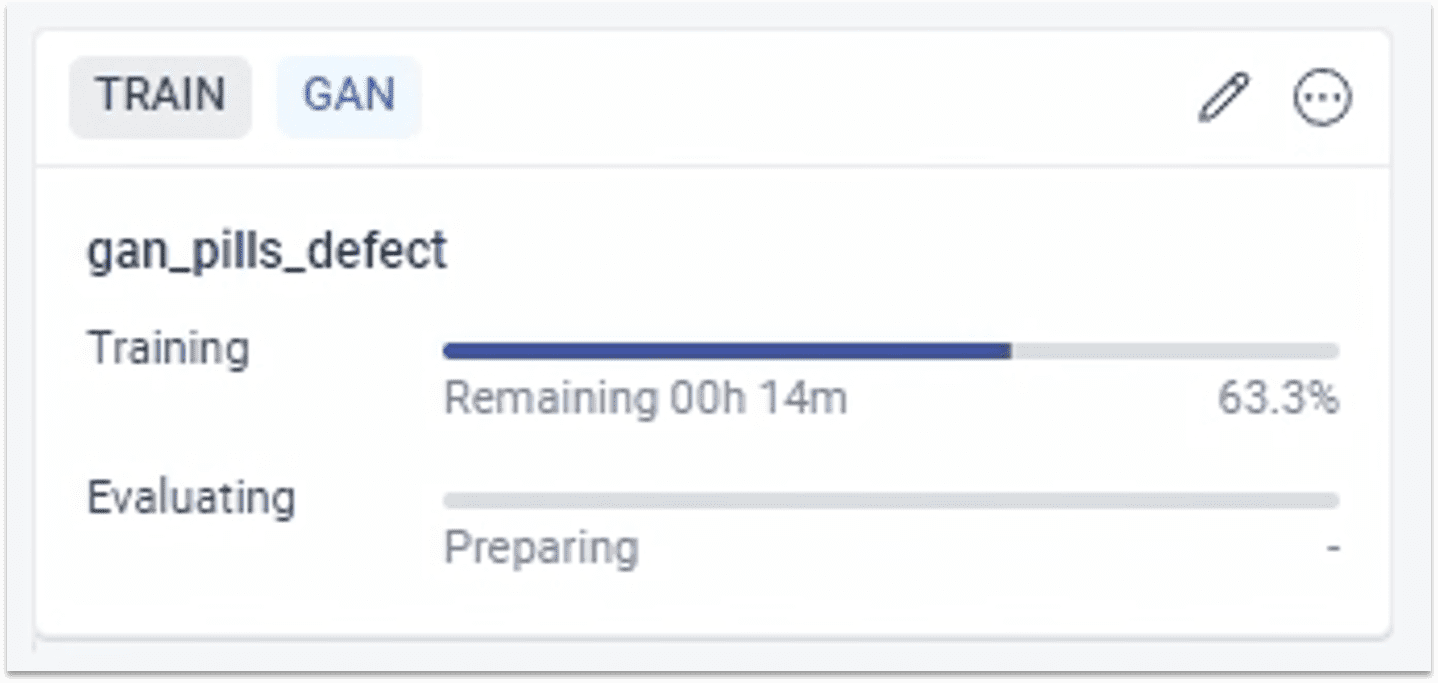
1.5.2 训练生成GAN模型
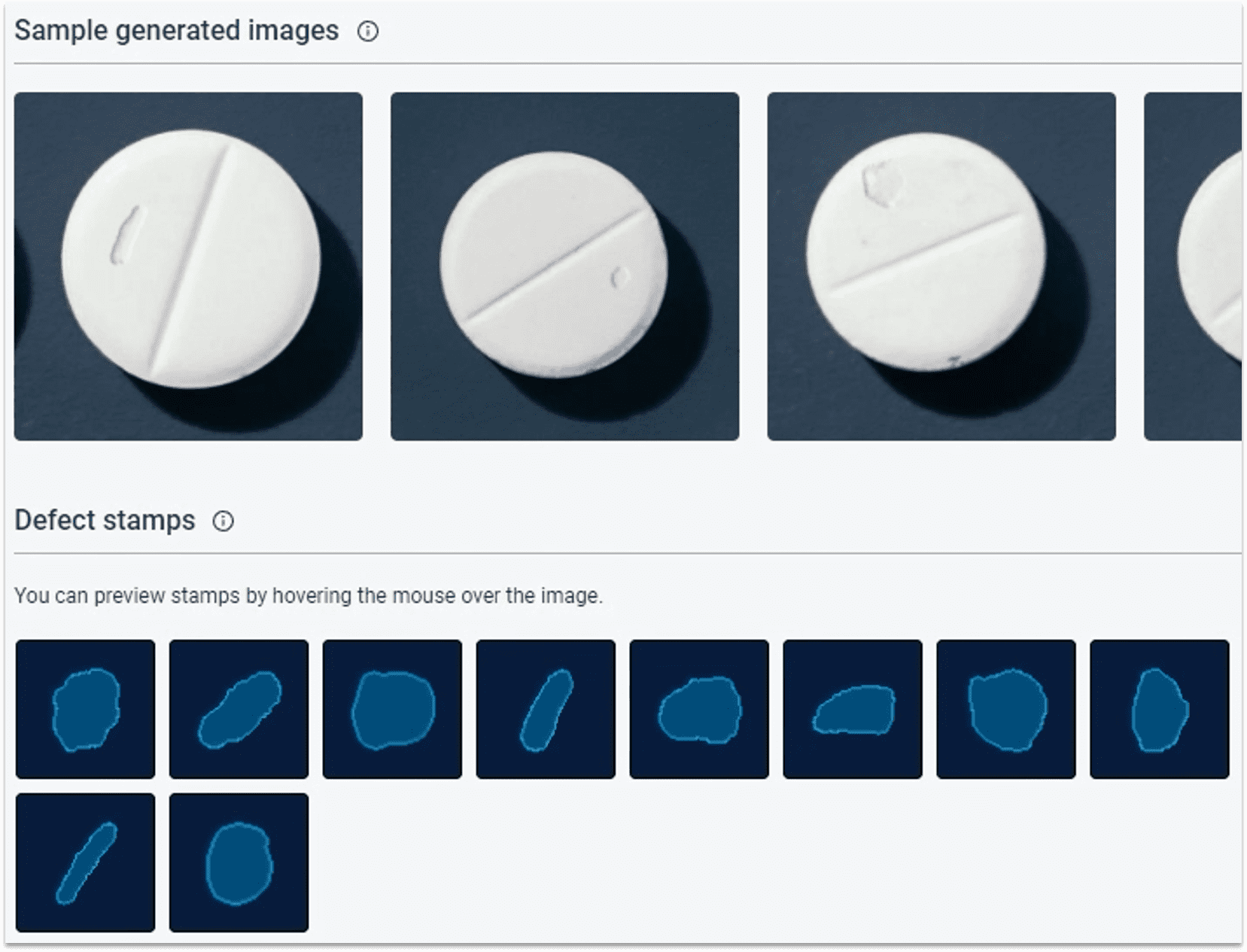
1.5.3 查看模型结果
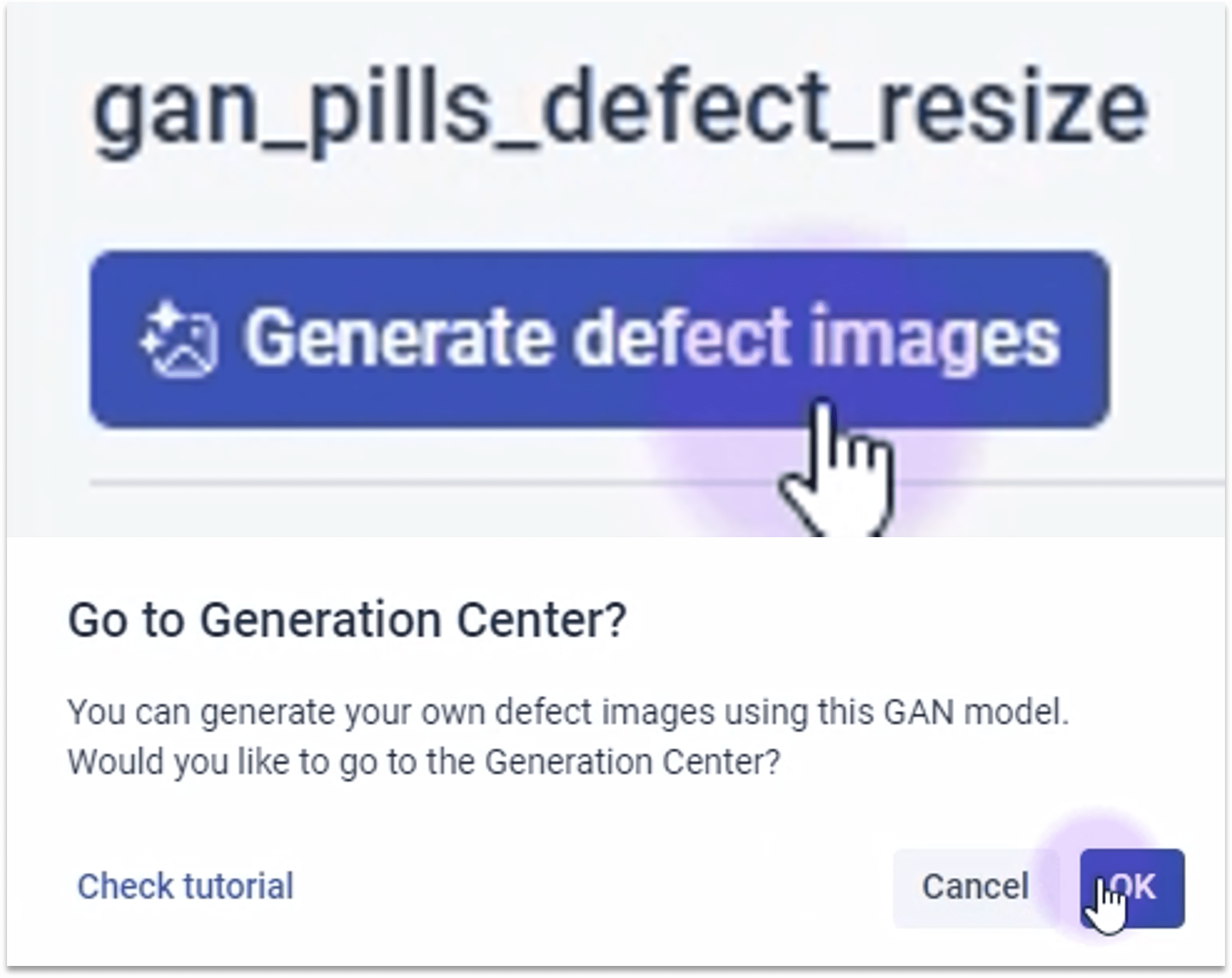
2.1.1 进入生成中心
将缺陷图像设置为训练集
将正常图像设置为测试集
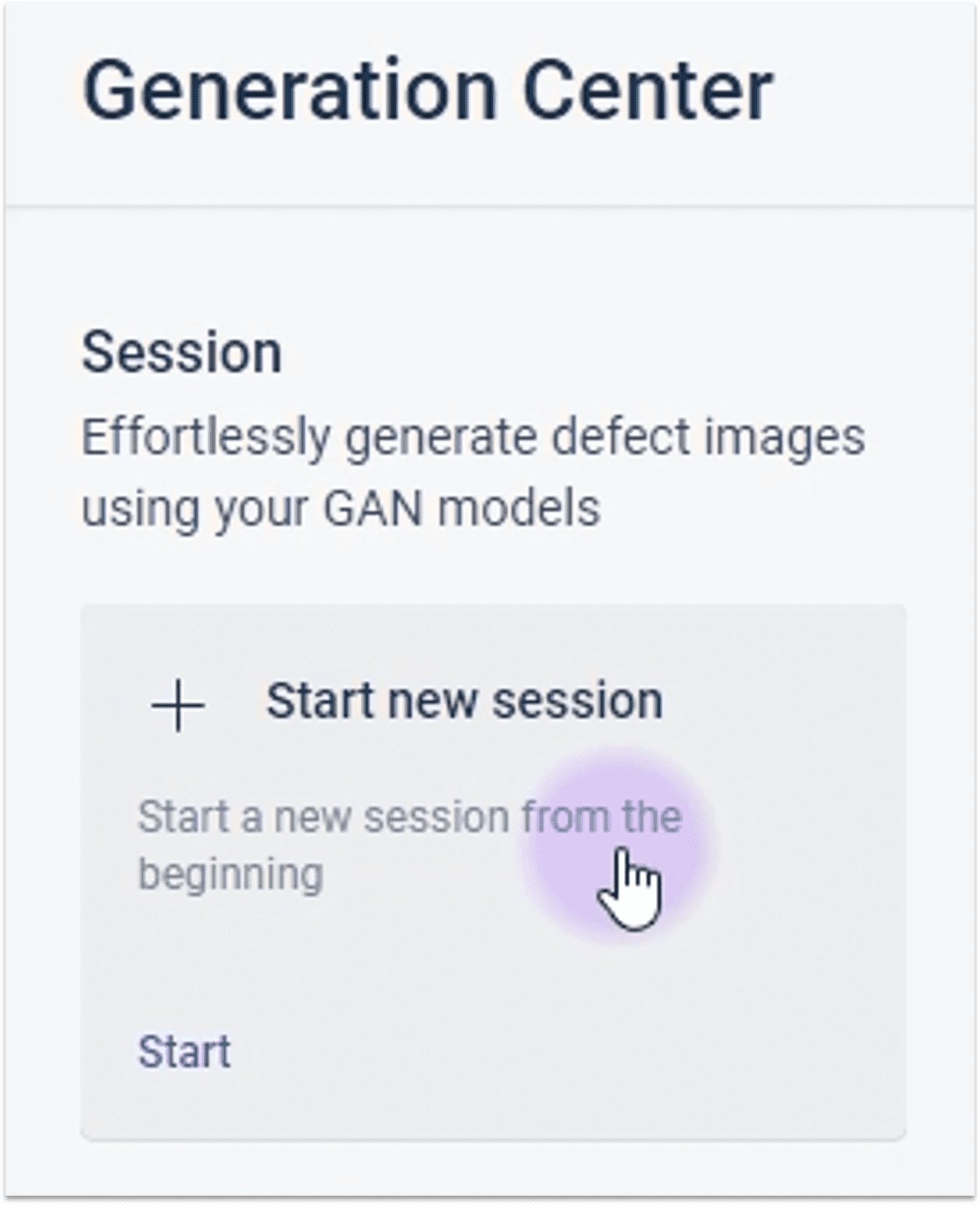
2.1.2 新建任务
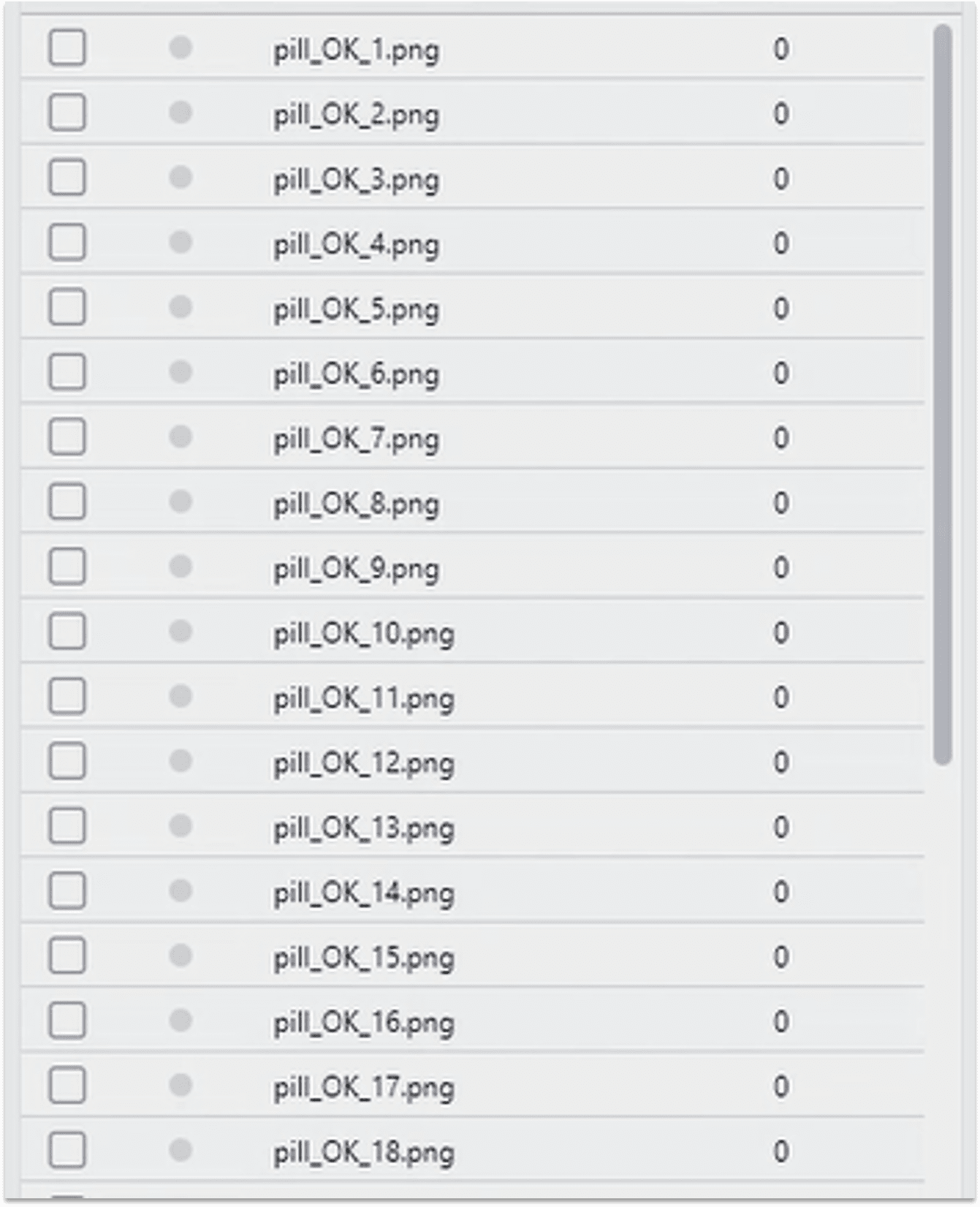
2.2.1 导入正常图像
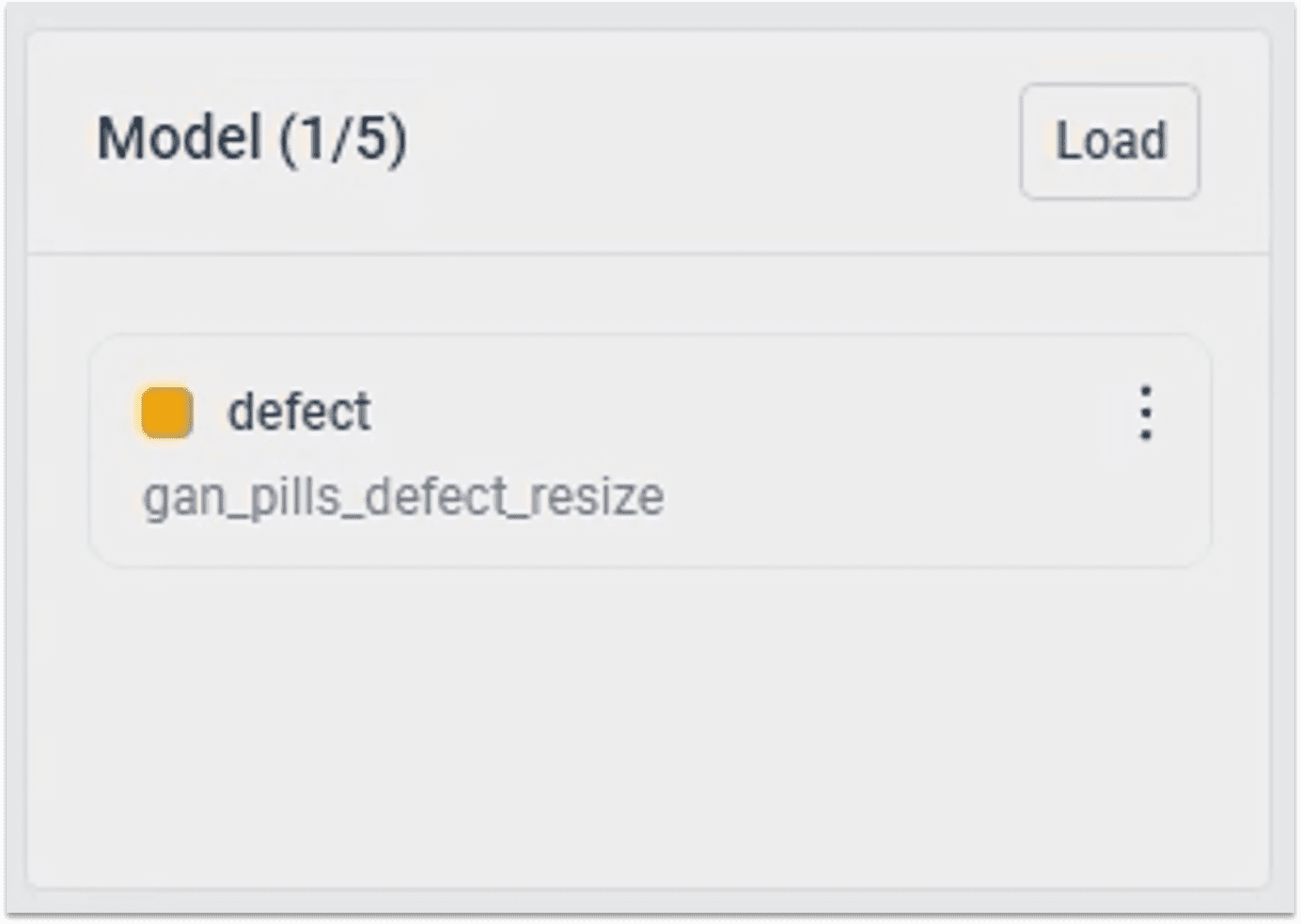
2.2.2 加载GAN模型
用于创建缺陷的图像数据
必须跟用于训练GAN模型的数据对应
后续将用这些正常图像生成缺陷图像
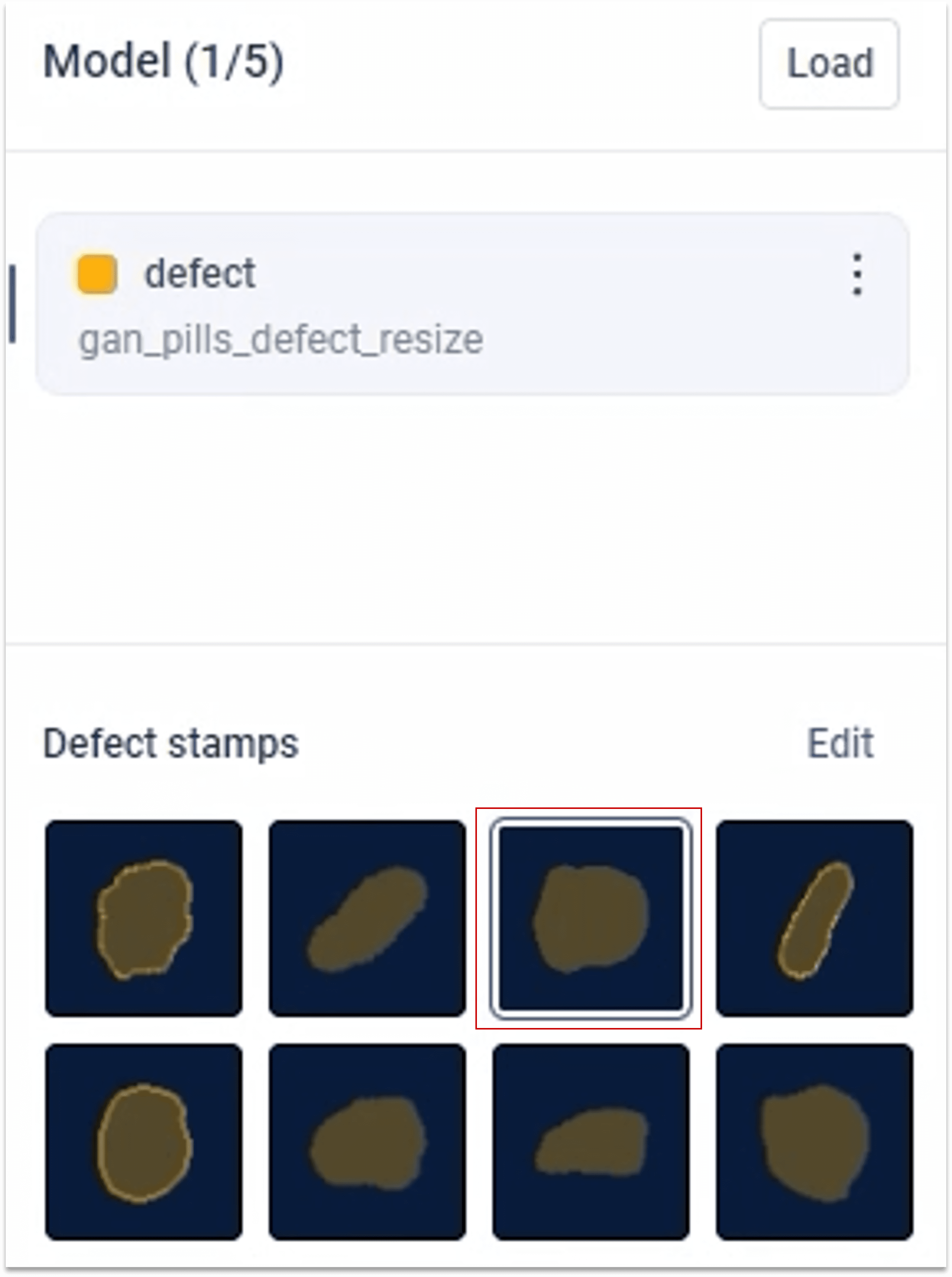
2.3.1 ① 选择缺陷生成类型
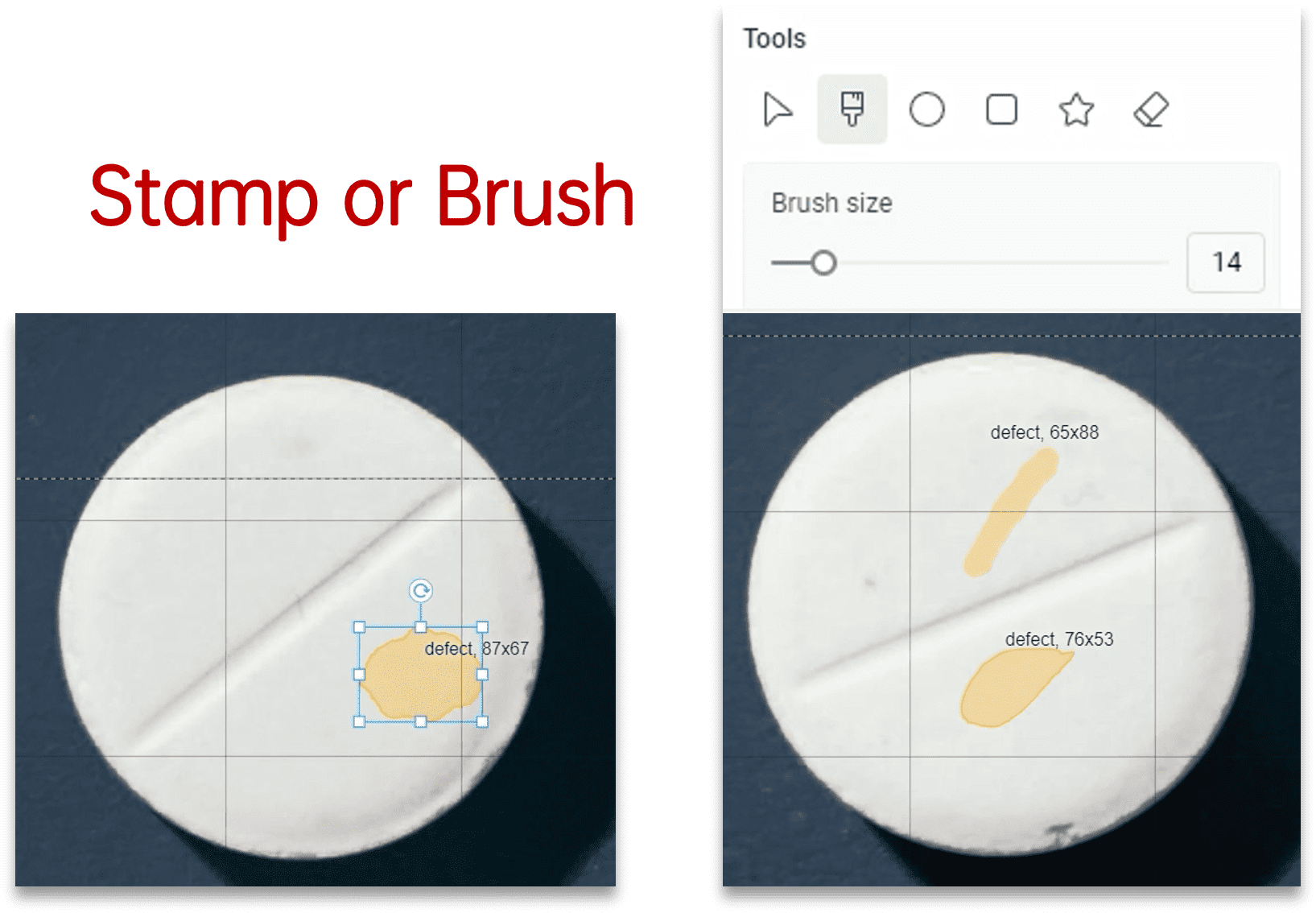
2.3.2 ① 绘制缺陷
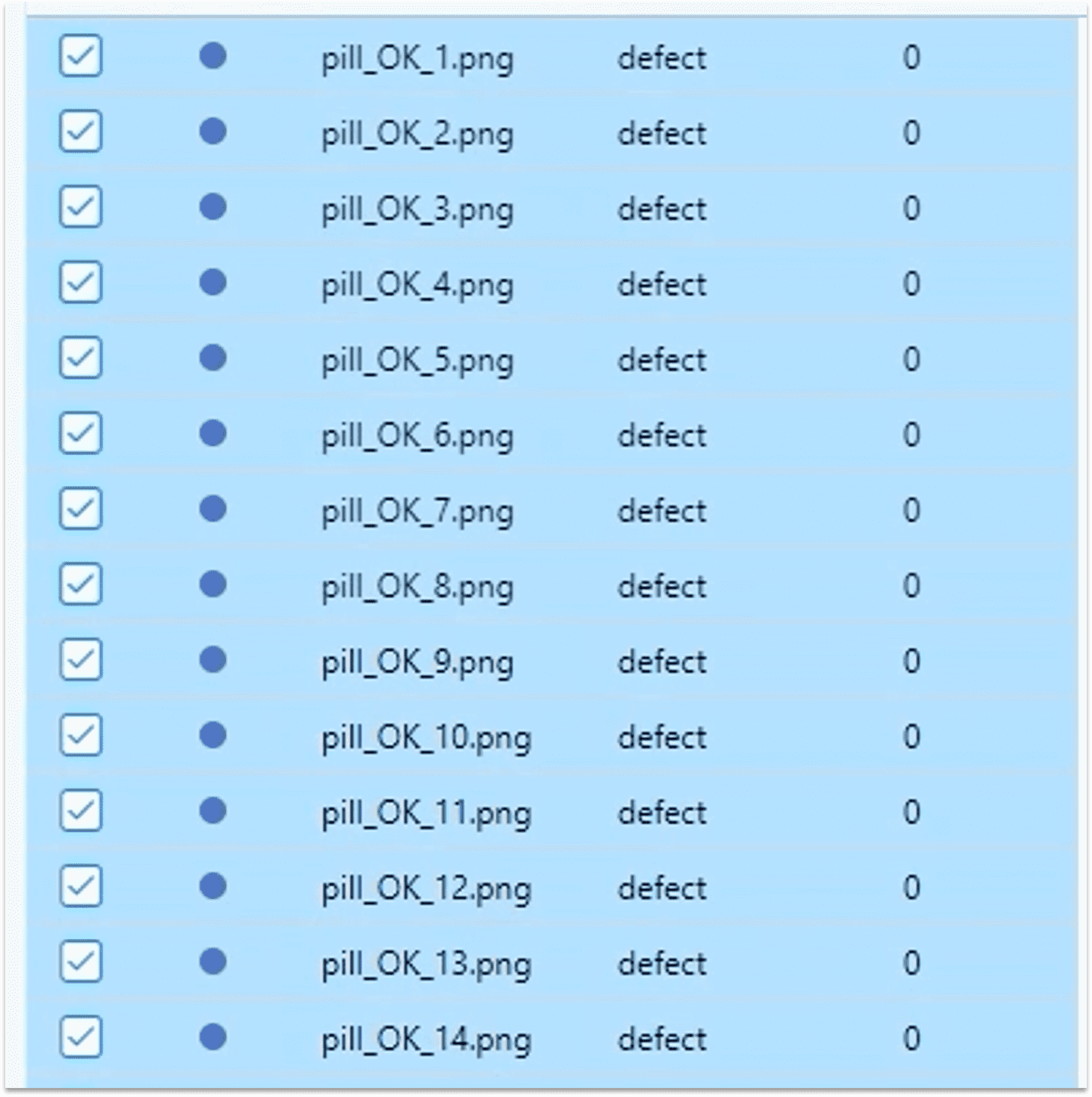
2.3.3 ① 完成绘制
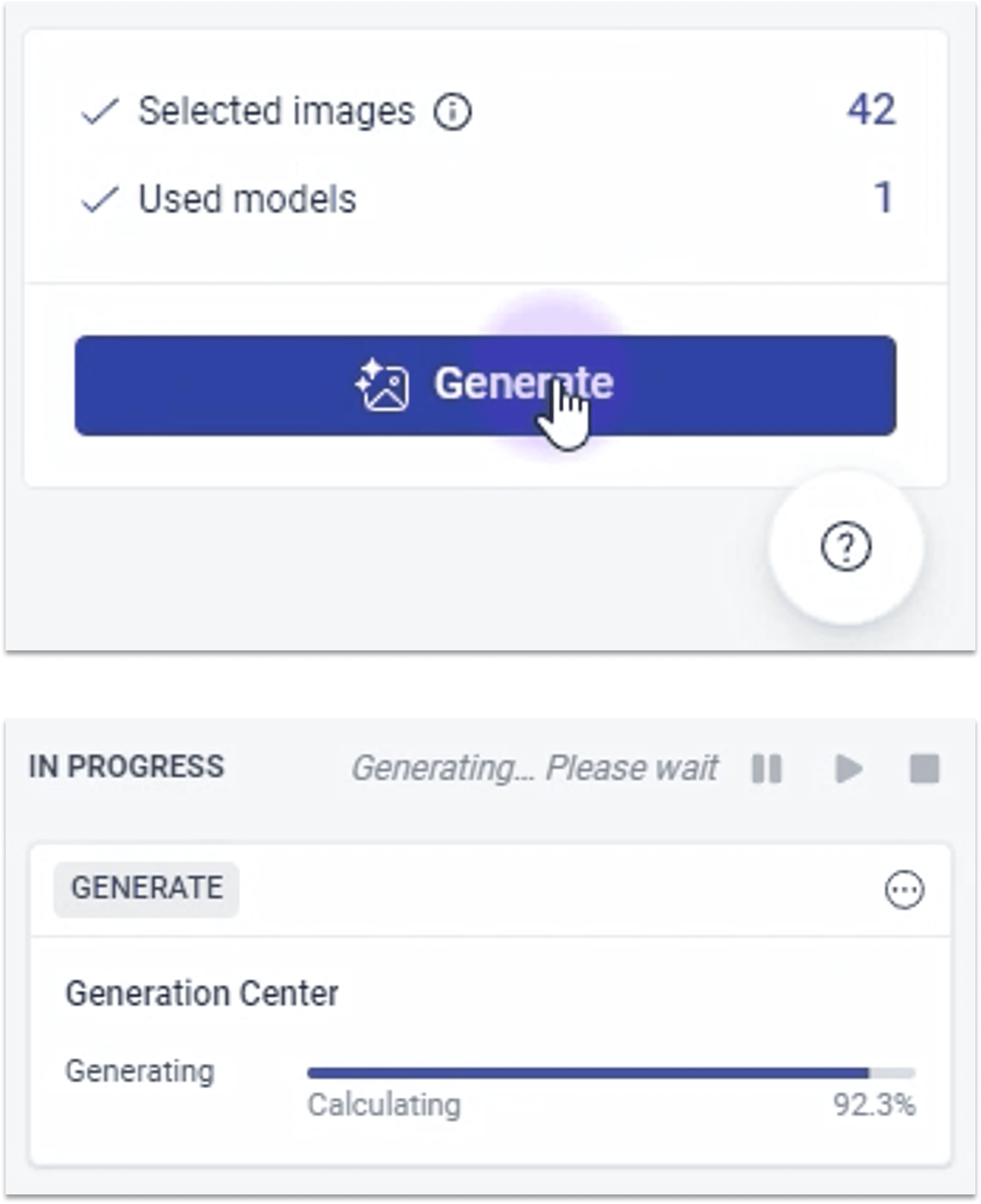
2.3.4 ① 准备生成
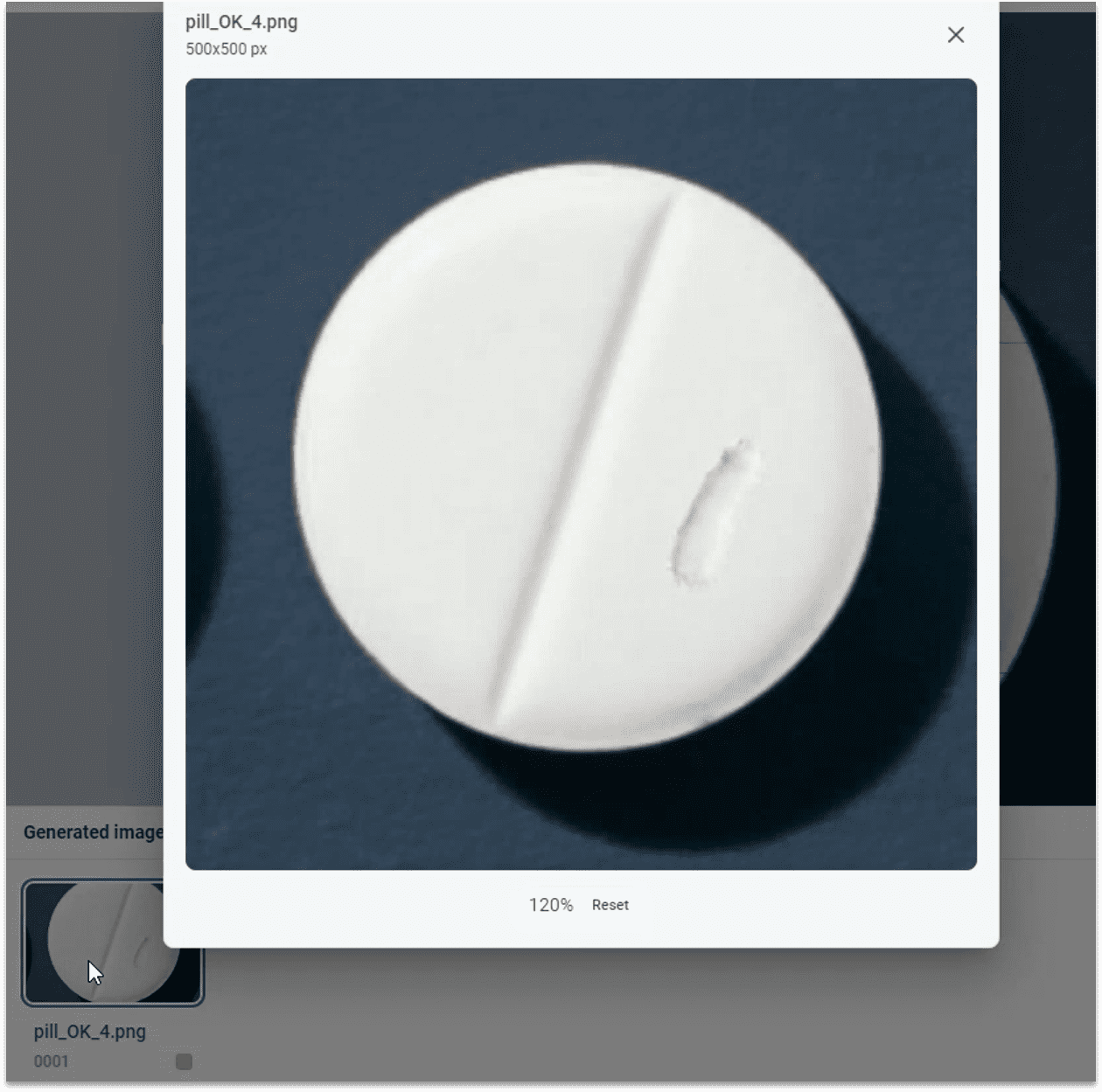
2.3.5 ① 生成缺陷图像
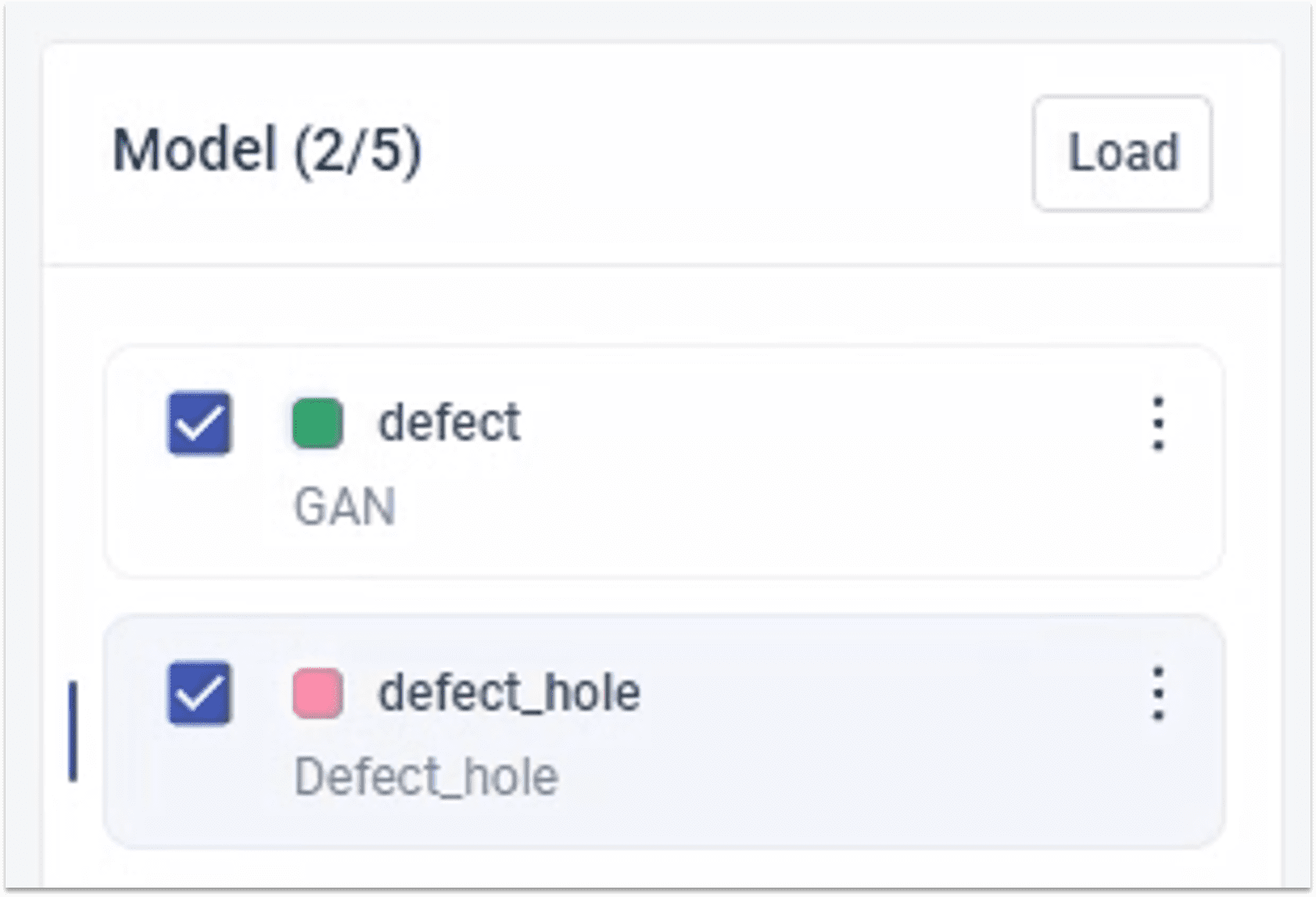
2.3.1 ② 选择缺陷生成类型

2.3.2 ② 设置缺陷数
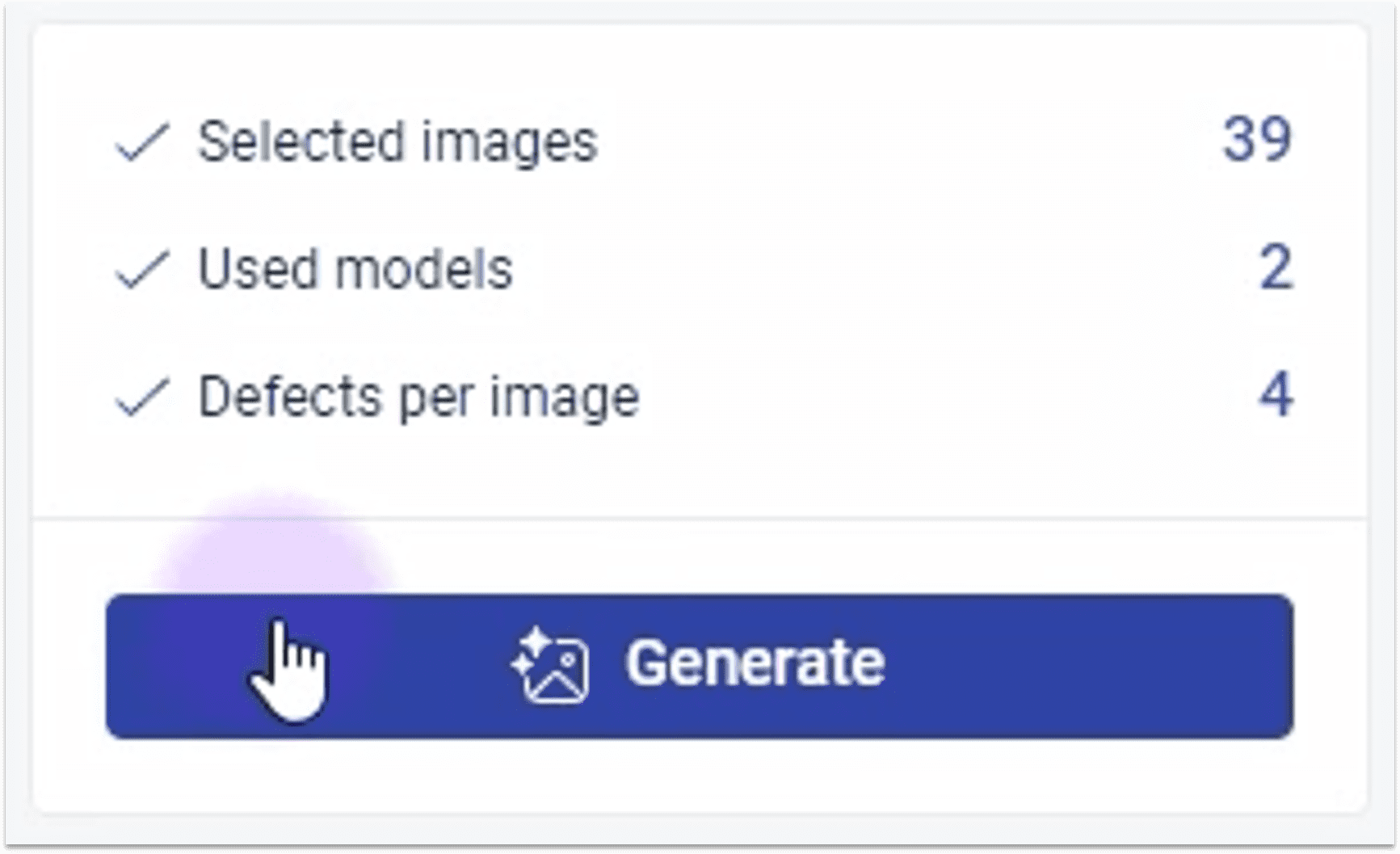
2.3.3 ② 生成缺陷图像

2.3.4 ② 得到缺陷图像
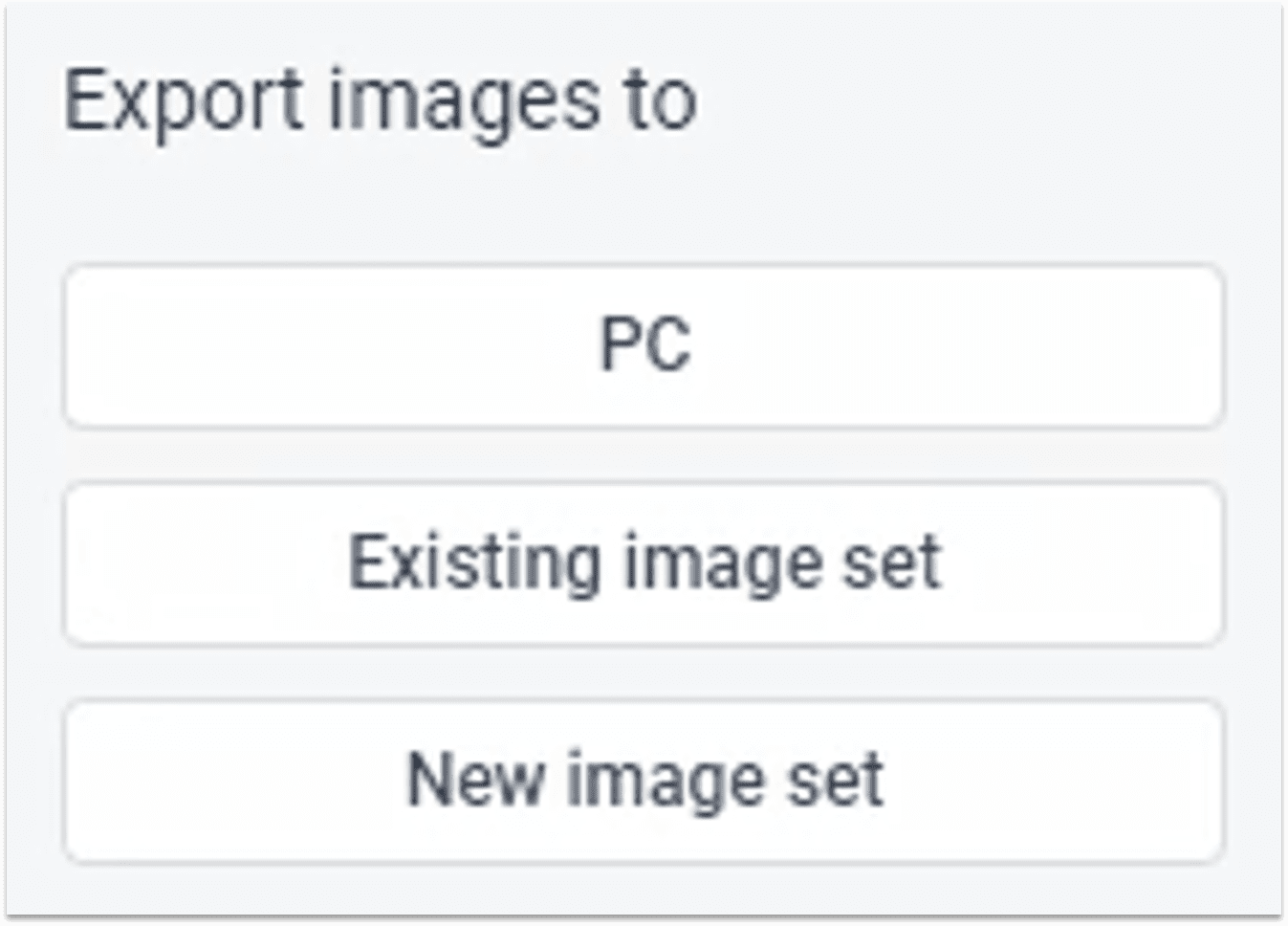
2.3.5 ② 导出图像数据
Neuro-T无监督学习模型
输出异常分类or检测模型操作步骤
友思特Neuro-T应用
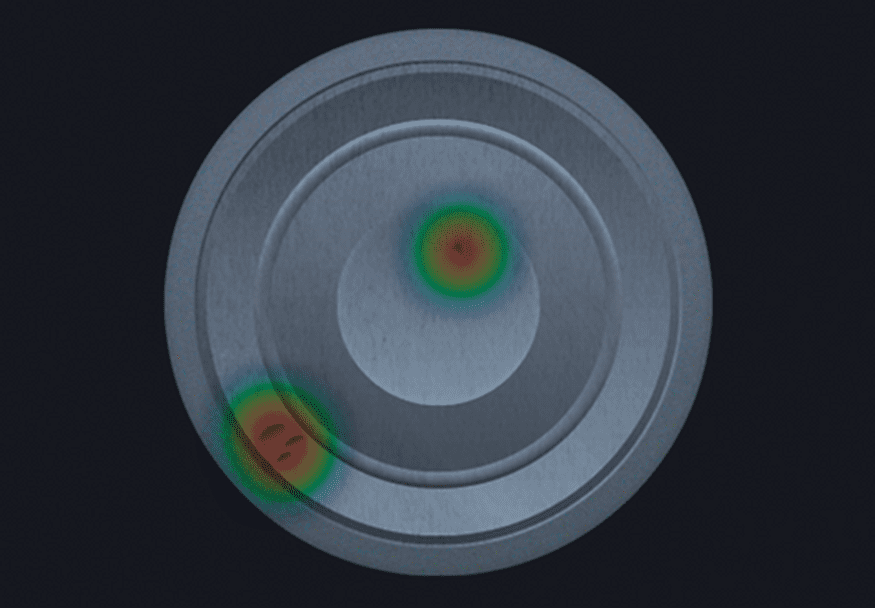
钢材表面缺陷检测
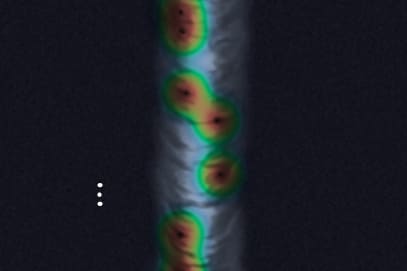
电池缺陷检测
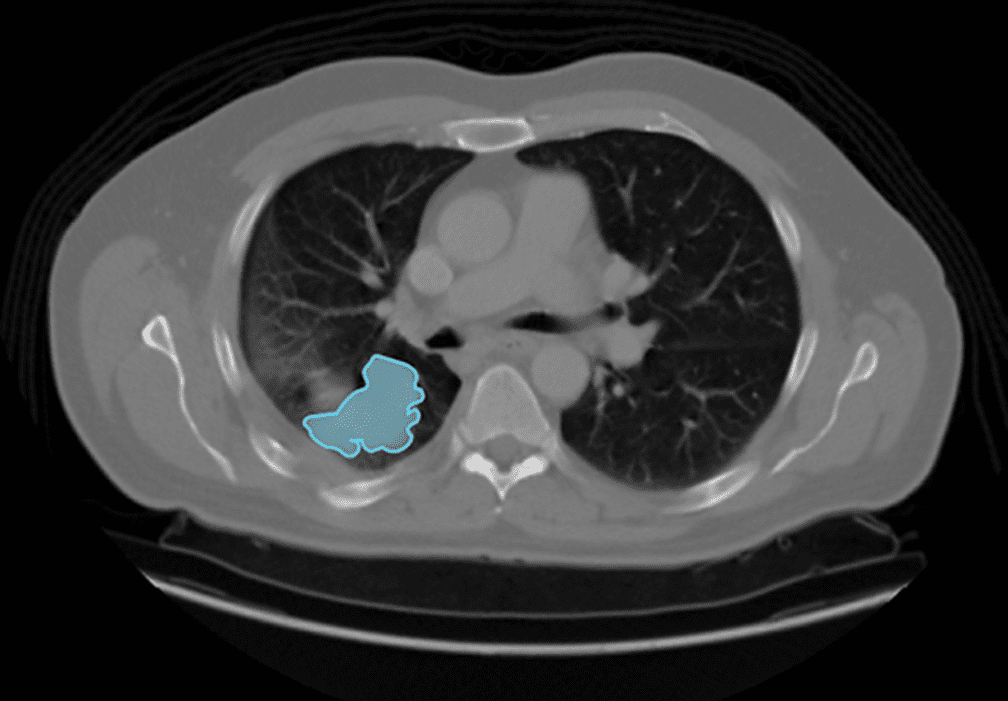
胸部CT病灶检测
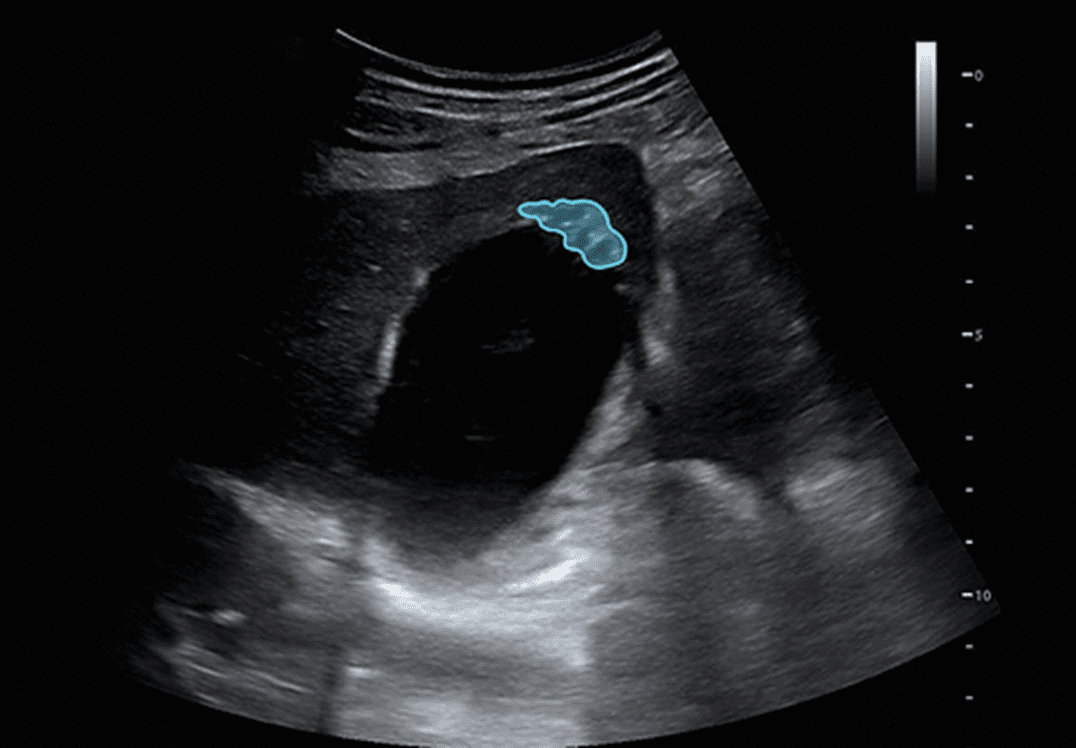
腹部超声异常检测
友思特 方案产品套装介绍

Neuro-T 自动深度学习软件
为工业专家设计的零代码自动深度学习模型训练器。提供用户友好的图形化界面,集成自动深度学习算法,结合自动标注功能,零代码编写,一键生成高性能视觉检测模型:包括分类、实例分割、目标检测、OCR、旋转、GAN、异常分类、异常分割等。

Neuro-R 快速部署实施推理API
快速部署实时推理API,无缝整合Neuro-T训练软件创建的模型,部署进视觉检测自动化设备的运行库。Neuro-R集成了各种API,能够快速融合和预处理图像,使对目标的推理速度满足实际生产需求,支持各种环境和编程语言。