

基于AI机器视觉平台Neuro-T的OCR(光学字符识别)模型,利用深度学习技术,训练强大的模型并优化其算法
结合前沿的传统图像处理技术,实现在各种复杂条件下的高效检测
可应用于各种行业项目中:工业质检、医疗物品分类、物流纸箱识别、交通标志分析、商品包装检测等

字符检测技术越来越重要
在当今的生活和工业环境中,字符检测技术逐渐成为不可或缺的一部分。无论是在日常生活中对文档的自动识别,还是在工业生产线上的智能化检测,准确提取和解析字符信息至关重要

这项技术的实施面临诸多挑战
首先,字符的多样性和变异性,如不同的字体、排版和手写体,导致识别过程的复杂性和易错性。其次,实际应用中常见的数据噪声和格式不规范问题会影响检测的准确性。最后,大规模数据处理对实时性能提出了严格要求,这对系统的处理能力带来了挑战。

利用深度学习技术实现各种复杂项目中的字符检测
为了解决这些难题,友思特基于AI机器视觉平台Neuro-T的OCR(光学字符识别)模型,推出了一套可广泛应用的字符检测视觉方案。该方案利用深度学习技术,训练强大的模型并优化其算法,结合前沿的传统图像处理技术,实现了在各种复杂环境下的高效字符检测。这不仅为日常生活提供了便利,也为工业应用提供了坚实的技术支持。



产品标识检查、条码识别、质量控制

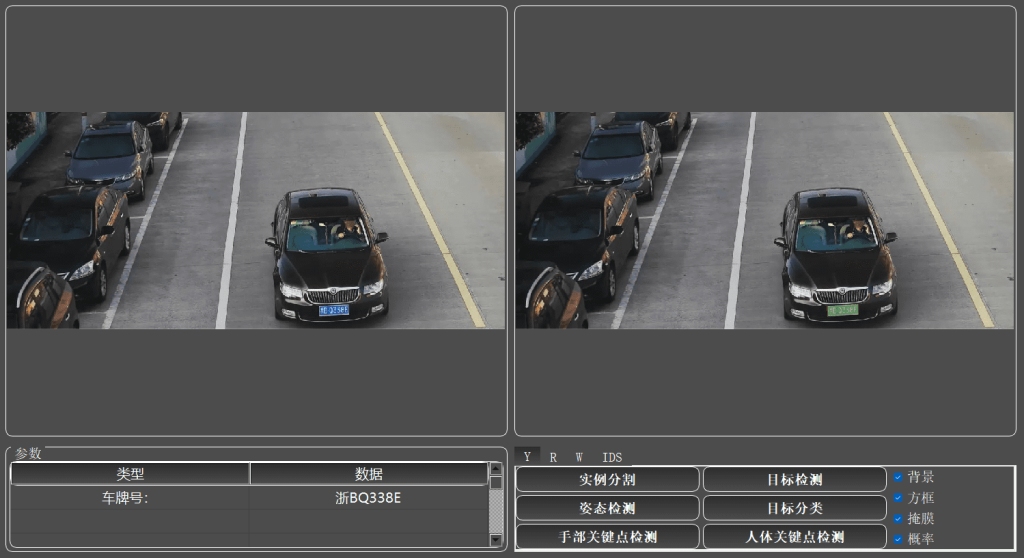
车牌识别、交通标志分析、证件自动读取

纸箱自动识别、货物跟踪、仓储管理

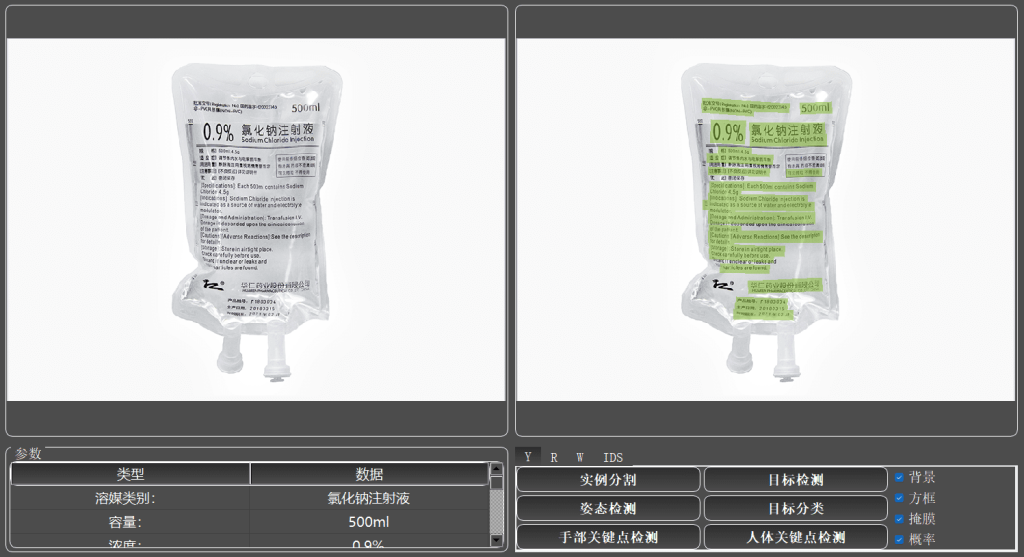
医药物品分类、处方识别、检测报告处理

商品包装生产日期检测、标签/库存扫描管理

支票处理、票据识别、银行卡信息提取

家电状态显示、远程控制信息提取

公文处理、公民身份识别、统计数据录入


将图像分类成不同的类别或OK/NG组别
简单分类目标缺陷的有无,精度高

分析图像中检测到的物体形状并圈选
准确识别并分割目标的缺陷区域,精度最高,适合占像素点少(低至10像素点)、形状较简单的目标

检测图像中物体的类别、数量并定位
识别和定位目标的缺陷区域,精度高,适合占像素点稍多、形状较复杂的目标
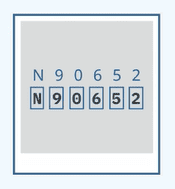
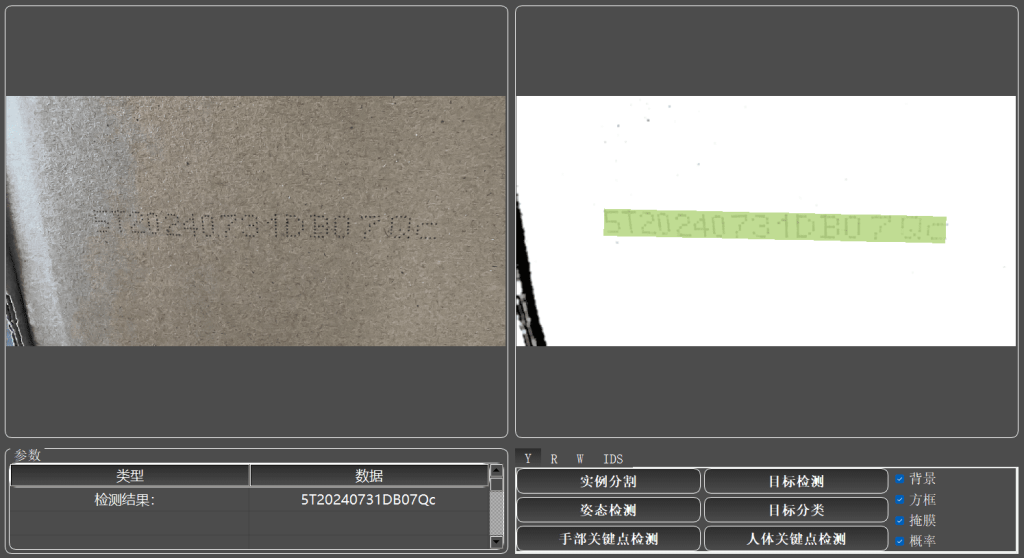
检测和识别图像中的字母、数字或符号
预置预训练模型,批量快速进行数据标注
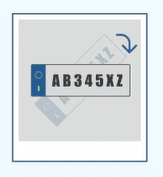
旋转图像至合适的方位
服务于其他模型类型,提高其他深度学习模型的识别准确率
学习图像中的缺陷区域并生成虚拟缺陷
人工生成目标的缺陷图像,弥补缺陷数据量不足的问题

在大量正常图像和少量缺陷图像上训练以检测异常图像进行分类
分类目标缺陷的有无,精度高于分类模型(可设置异常阈值),主要适用于数据缺乏场景

在大量正常图像和少量缺陷图像上训练以检测异常图像并定位缺陷位置
准确识别并分割异常目标的缺陷区域,精度略低于实例分割模型(可设置异常阈值),主要适用于数据缺乏场景
广泛适用性
支持不同目标产品背景、图像类型、应用领域的字符识别

强大的预处理功能
结合图像处理算法滤除噪声和提取字符特征,提升字符识别准确性

自动化处理
自动化字符检测和转换,减少人工辨别和输入的需求,提高产线效率

灵活的格式输出
支持字符检测结果多种数据格式输出,如txt、pdf、xlsx、csv等,方便后续处理和集成

预训练模型辅助标注
平台提供预训练OCR模型辅助快速批量标注不同文本环境的字符,缩短视觉项目周期

高效数据处理
通过正则化匹配滤除、提取、替换所检测的字符,实现从对象检测到处理输出的完整流程






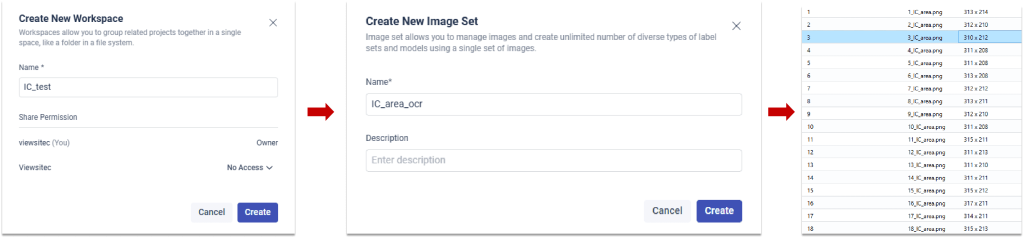


可以使用手动标注或自动标注的方式对图像进行字符内容的标注
手动标注:
将图像中的文字旋转到合适的朝向->
选择绘制矩形框、设置大小写类型以及字符排布方向->
在图像中需要标注的字符位置绘制矩形框并填写字符内容

自动标注:Neuro-T自动学习平台的OCR深度学习模型提供了两种自动标注方式
自动标注方式一:预训练模型自动标注
使用Neuro-T平台自带的预训练OCR模型对数据集进行自动批量快速标注,再微调标注结果。
自动标注方式二:自定义模型自动标注
手动标注部分图像来训练OCR模型,选择用于标注的OCR模型,再应用到想要标注的图像上即可。



Neuro-T
为工业专家设计的零代码自动深度学习模型训练器。提供用户友好的图形化界面,集成自动深度学习算法,结合自动标注功能,零代码编写,一键生成高性能视觉检测模型:包括分类、实例分割、目标检测、OCR、旋转、GAN、异常分类、异常分割等。

Neuro-R
快速部署实时推理API,无缝整合Neuro-T训练软件创建的模型,部署进视觉检测自动化设备的运行库。Neuro-R集成了各种API,能够快速融合和预处理图像,使对目标的推理速度满足实际生产需求,支持各种环境和编程语言。

友思特 IDS工业相机
Neuro系列深度学习软件可以搭配IDS高精度工业相机进行工作。IDS工业相机包括uEye+ CMOS工业相机、Ensenso 3D立体相机、NXT一体化推理相机,可以根据各类应用需求提供不同感光芯片尺寸、帧率、分辨率、接口的相机,应用可能性几乎不受任何限制。
